

La disponibilidad (availability) de un sistema es la proporción de tiempo en la que puede atender a sus usuarios. Se mide en 9s (nueves, nines), por ejemplo 5 9s significa 99.999% de uptime (tiempo funcionando). Hasta ahí parece fácil, ¿no?
No.
Por si no hicieron el cálculo, 99.999% uptime implica 1 – 0.99999 = 0.00001 de downtime (tiempo sin funcionar). Es decir que en un año sólo podemos tener un downtime de 0.00001 * 365 * 24 * 60 = 5 minutos y 15.36 segundos. En el mejor de los casos, 5 minutos es lo que tardo en leer una alerta en el celular y encender la computadora. Primer tip del artículo: La alta disponibilidad y la necesidad de intervención humana no se llevan bien, es necesario automatizar.
A partir de la disponibilidad podemos definir Service Level Objectives (SLOs), y ofrecer a nuestros clientes Service Level Agreements (SLAs).
Un SLO es un objetivo interno de disponibilidad, y sirve para guiar decisiones técnicas y de negocio. Por ejemplo, se puede definir como SLO un 99.9% de disponibilidad por cada trimestre (es decir 2 horas y 11 minutos de downtime por trimestre), y de acuerdo al downtime que se haya acumulado en este trimestre se puede optar por postergar ciertas operaciones que aumenten el riesgo de una caída del sistema, como un release de una versión mayor, una migración de infraestructura o un simulacro de recuperación de desastres.
Un SLA es un acuerdo legal que asume la empresa proveedora del servicio con sus clientes, e incluye un objetivo de Disponibilidad, una forma de medir el objetivo (por hora, mensual, por request, etc) y una serie de medidas a tomar si el objetivo no se cumple. Por ejemplo, para el servicio manejado de base de datos relacional AWS RDS en su configuración multi-AZ, Amazon Web Services establece una disponibilidad de 99.95% (3.5 9s) medida mensualmente, y se compromete a devolver un 10% de los cargos mensuales si la disponibilidad está entre 99.95% y 99%, 25% de los cargos mensuales si la disponibilidad está entre 99% y 95%, y 100% de los cargos mensuales si la disponibilidad está por debajo de 95%. Esta información se puede encontrar acá: https://aws.amazon.com/rds/sla/

Pueden encontrar la mayoría de los SLAs de Amazon Web Services en este link: https://aws.amazon.com/legal/service-level-agreements/. Lamentablemente, no están todos. Por ejemplo, no está el de VPC (el servicio de red de Amazon Web Services), el cual si mal no recuerdo tiene 5 9s.
¿Para qué me sirve todo esto? Para comprender mejor cómo puede fallar mi sistema. Si comprendo cómo puede fallar, puedo implementar estrategias de mitigación y recuperación. Segundo tip del artículo: Si comprendo cómo funciona mi servicio, puedo ofrecer a mis clientes compromisos y garantías que sé que voy a poder cumplir.
Claramente no alcanza con conocer el SLA de un servicio, ya que para construir nuestros sistemas usamos varios servicios al mismo tiempo, combinados con nuestro propio código. Así que analicemos con un ejemplo la disponibilidad de un servicio.
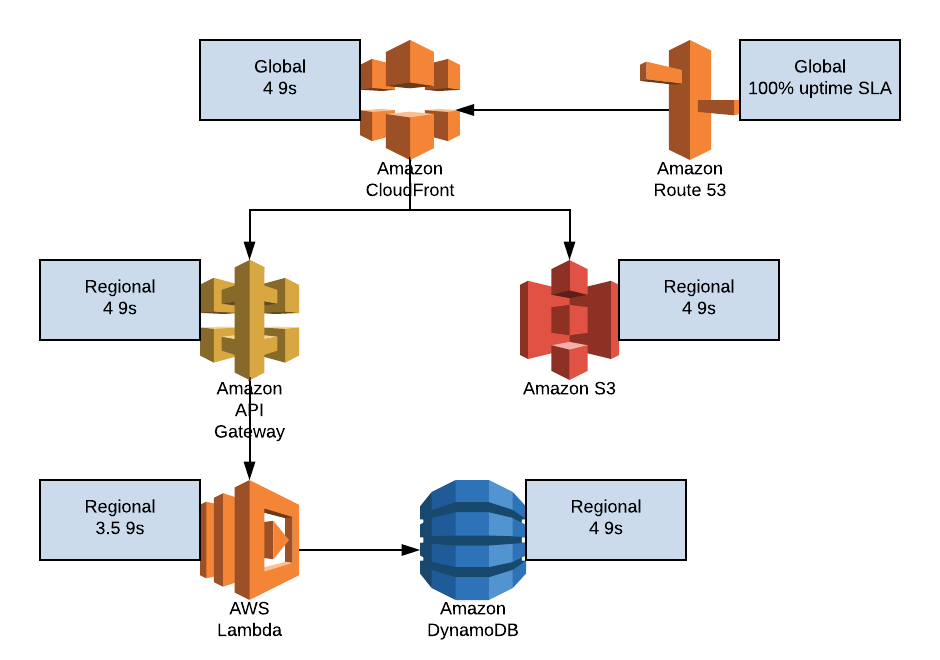
Vamos a tomar como ejemplo una arquitectura serverless muy simple, para comprender cómo se agregan los distintos SLAs y cómo se calcula la disponibilidad. Luego podemos discutir qué pasa con servicios como EC2 donde la API tiene 4 9s de uptime y cada VM tiene 1 9 de uptime, o cuando nos metemos con un orquestador de containers.
Tenemos 3 posibles requests:
- Un GET de contenido estático: pasa por Route 53 y CloudFront. Puede ser un cache hit en CloudFront y ser servida directamente desde CloudFront, o un cache miss y ser servida desde S3
- Un GET de contenido no estático: pasa por Route 53 y CloudFront. Puede ser un cache hit en CloudFront y ser servida directamente desde CloudFront, o un cache miss y pasar por API Gateway, ejecutar una función Lambda y realizar una lectura en DynamoDB
- Un PUT, POST o DELETE: pasa por Route 53, CloudFront, y va a pasar siempre por API Gateway, Lambda y DynamoDB
Estamos asumiendo que:
- No hay cache de writes.
- Todas las requests al servicio de backend (Lambda) implican siempre un acceso a la base de datos (no sería el caso si, por ejemplo, incorporáramos autenticación y autorización, y un usuario no autorizado intentara escribir en la base de datos).
- El usuario no puede escribir en el bucket de S3, directa o indirectamente. El bucket sólo contiene contenido generado por los desarrolladores.
- Tenemos un cache hit ratio de 95% (es decir, el 5% de las requests van del CDN al backend). Más info sobre cache hit ratio en CloudFront.
Para el contenido estático, el 95% de las requests pasan por el CDN, que tiene 99.99% de availability, y el 5% pasan por el CDN (99.99%) y S3 (99.99%). Entonces, la availability para las requests servidas desde el CDN es 99.99%, y para las que van a S3 es 0.9999 * 0.9999 = 0.9998 = 99.98%. La disponibilidad total es 0.999895, o sea lo suficientemente parecido a 4 9s.
Para GETs a la base de datos, el 5% de las requests no servidas por CloudFront van a pasar por CloudFront (99.99%), API Gateway (99.99%), Lambda (99.95%) y DynamoDB (99.99%). El cálculo para esas requests es 0.9999 * 0.9999 * 0.9995 * 0.9999 = 0.9992. El cálculo final es 0.999865, de nuevo bastante parecido a 4 9s.
Para POSTs, PUTs y DELETEs, ninguna request es servida por CloudFront, y la disponibilidad es 0.9992, o sea apenas por encima de 3 9s.
Todo esto es para la infraestructura, ¡pero también hay que tener en cuenta el código! Si nuestro código funciona mal para una request cada 1000 (es decir el 0.1% de las requests fallan por culpa de nuestro código), los números cambian a 0.9989 (suficientemente parecido a 3 9s) para GETs y 0.9982 (ya no tan parecido a 3 9s) para POSTs, PUTs y DELETEs. El contenido servido desde S3 no se ve afectado, ya que no se ejecuta nuestro código.
Para EC2 y cualquier servicio respaldado por EC2 (como Fargate), vamos a ampliar un poco sobre el cálculo de probabilidades. La regla para sumar probabilidades de eventos no mutuamente excluyentes es P(A∪B)=P(A)+P(B)−P(A∩B). En nuestro caso, el evento es la falla de un servicio, y para el cálculo anterior podíamos simplificarlo como el producto de la probabilidad de que cada servicio funcione bien (0.9999 * 0.9999), ya que para cada uno de los caminos de requests que encontramos la caída de un servicio cualquiera implica la caída total del sistema.
En EC2, la caída de una VM no implica la caída total del sistema, sino una performance degradada. Para simplificarlo, vamos a asumir que si tenemos X VMs o más nuestro servicio funciona perfectamente y si tenemos menos de X VMs nuestro servicio no funciona en lo absoluto. En un escenario realista deberíamos analizar el comportamiento de los servidores cuando se sobrecargan y el tiempo que se tarda desde que se envía la request a EC2 de crear un servidor hasta que el servidor está disponible para servir tráfico, pero son cuestiones muy dependientes de la aplicación.
Si cada VM tiene 90% de uptime, tenemos 2 VMs y necesitamos al menos 1 VMs para que el sistema funcione, la probabilidad de que cada una falle es de 0.1, y la probabilidad de que en un determinado momento ninguna esté fallando es (0.9)^2 = 0.81. Pero no nos interesa que hayan dos funcionando, sino una sola. En ese caso, con 2 VMs vamos a tener 0.99 de disponibilidad, con 3 VMs 0.999, y así sucesivamente.
Si necesitamos 2 VMs para que el sistema funcione, el cálculo es un poquito más difícil. Vamos a considerar todos los escenarios posibles: ambas VMs funcionando, una funcionando y la otra no, ambas no funcionando. De esos escenarios, vamos a calcular y sumar las probabilidades de los que dejan a nuestro sistema funcionando, en este caso sólo ambas VMs funcionando. Cada VM tiene 0.9 probabilidad de funcionar, la probabilidad de que ambas funcionen es 0.9 * 0.9 = 0.81.
Si tenemos 3 VMs los escenarios posibles son: las 3 VMs funcionando, 2 funcionando y una sin funcionar, una funcionando y 2 sin funcionar, todas sin funcionar. La probabilidad de que todas funcionen es (0.9)^3 = 0.729. La probabilidad de que dos funcionen y una falle es 0.9 * 0.9 * 0.1 para cada una, multiplicado por 3 ya que son 3 combinaciones posibles (si fueran 4 VMs serían 6 combinaciones posibles, por ejemplo), resulta en 0.243. La suma de las probabilidades es 0.729 + 0.243 = 0.972. Para 4 VMs, la probabilidad de tener todas, 3 o 2 funcionando es 0.9963, es decir 2.5 9s. Para lograr más de 99.9% de disponibilidad necesitamos 5 VMs, y logramos 3.5 9s.
Por supuesto, a estos cálculos de VMs hay que multiplicarlos por la disponibilidad de los otros servicios que usemos (incluyendo la API de EC2, que tiene 4 9s) y de nuestro código.
Se terminó volviendo bastante estadístico, pero los SLOs se tratan de eso, objetivos estadísticos. Como ya mencionamos, los SLAs tienen algo más que la disponibilidad, también incluyen la compensación que se ofrece al cliente si no se cumple el acuerdo. Es importante este punto, porque hay que entender que los SLAs no son promesas de disponibilidad para un servicio, son acuerdos de hacer lo económicamente posible (literalmente «AWS will use commercially reasonable efforts …») por cumplir esos números, y de compensar económicamente al cliente si no se cumplen.
¿Cómo podemos evitar compromisos que no podemos cumplir? Comprendiendo cómo fallan nuestros sistemas, y planteando acuerdos para compensar a nuestros clientes cuando no se cumplan los parámetros que especificamos. No es un «si no se cumplen», es un «cuando no se cumplan». Tercer tip del artículo: Dado suficiente tiempo, cualquier sistema va a fallar. Por eso es importante entender cómo fallan nuestros sistemas.
Una eterna discusión es cómo definir los SLOs y SLAs. ¿Cuántos 9s necesita nuestro sistema? En parte es una decisión técnica, porque nunca vamos a poder crear un sistema con más 9s que los del sistema con menos 9s del que dependemos, así que un requerimiento de 5 9s puede implicar escribir nuestro propio load balancer (el de AWS no nos sirve, tiene 4 9s), drivers de red, etc. Pero principalmente debería ser una decisión de negocio, teniendo en cuenta los perfiles de usuario y cómo y para qué acceden al sistema (por ejemplo, si los usuarios acceden por una conexión 4G que tiene con suerte 2 9s, ¿para qué querríamos implementar más que eso en nuestro sistema?)
¿Ustedes cómo definen sus SLOs y SLAs? O si no los definen, ¿cómo miden la disponibilidad de sus sistemas?
Más importante aun, ¿qué tan bien comprenden cómo fallan sus sistemas?

Aprende a gestionar +100 Pipelines en AWS con CDK
Aprende a gestionar +100 Pipelines en AWS con CDK Descubre...
Leer más
Cómo Azure Databases y la IA revolucionan las aplicaciones modernas (RAG y Copilot)
Cómo Azure Databases y la IA revolucionan las aplicaciones modernas...
Leer más
Cómo crear Agentes de IA con Microsoft Copilot y Azure
Cómo crear Agentes de IA con Microsoft Copilot y Azure...
Leer más
El futuro sin contraseñas: WebAuthn, FIDO2 y el reto de la Criptografía Cuántica
El futuro sin contraseñas: WebAuthn, FIDO2 y el reto de...
Leer más