
Reducción de costos en GCP en pocas palabras
En este artículo cubriremos factores clave de reducción de costos en BigQuery, desde escribir consultas correctamente hasta cómo construir una arquitecturas de datos. Todo esto con un solo objetivo: El reducir costos.
Las consultas en BigQuery cuestan dinero
El modelo de costos – En BQ es “Paga conforme usas”: $5 dólares por terabyte escaneado al ejecutar cada consulta.
Regla de oro – En la mayoría de los casos, si tu consulta cuesta más de $1, estás haciendo algo mal.
Mantente en control de tus costos – Ésta herramienta puede ayudarte increíblemente con eso:
BigQuery Mate – (Extensión gratuita para Chrome)
Qué hacer y qué no
1. Trata de evitar el “Select *”; De esta manera evitarás el pagar por datos en columnas que no necesitas realmente en tus resultados.
2. Usar la clausula “Limit” en una consulta no limitará la cantidad de datos escaneados.
3. Usa la opción “Table Preview” para ver menos líneas de la tabla (En lugar de usar “Limit”) – Esto es gratis
4. Hay protecciones más extremas dentro de los ajustes de la consulta – Sección de ajustes avanzados: “Maximum bytes billed”. El usar esta opción limitará el número de bytes que serán cobrados por esta consulta. Si la consulta llega a sobrepasar este límite, ésta fallará (Sin ningún cargo).
5. Usa el el tiempo de expiración de tablas por defecto para eliminar datos cuando ya no son necesarios – Esto te ahorrará costos de almacenamiento.
6. Usa inserciones en stream sólo si tus datos deben estar inmediatamente disponibles para ser consultados. En otras palabras; ¡no uses inserciones en stream a menos que realmente lo necesites! Cuesta dinero.
7. Cuotas de uso – Puedes limitar la cantidad de datos escaneados por día o por proyecto, pero no por usuario. Es una buena práctica el poner un límite diario que te ayudará a siempre permanecer en la zona segura en términos de costos.
Mejorar el rendimiento (y costos)
1. Particiona tus tablas – ¡Las que son significativamente grandes!
Esto ayudará a mejorar tu rendimiento y costos.
2. Existen varias maneras de particionar tus tablas – Las más comunes y las más eficientes la mayoría del tiempo en relación a rendimiento y precio son las que usan el método time-partitioned tables.
3. Desnormaliza cuando sea posible. – BigQuery, por su naturaleza, está diseñado para utilizar una tabla gigante. El usar una tabla normalizada con relaciones a otras resultará en muchos joins, y por lo tanto, en un incremento de costos como también reducción del rendimiento.
4. Usa “Order By” sólo en la consulta más exterior o dentro de cláusulas de ventana (funciones analíticas). Mueve las operaciones complejas hacia el final de la consulta.
5.Evita auto-uniones. Usa una función de ventana como alternativa.
6. Lo mismo aplica con Cross-joins
Arquitectura de datos para reducir costos
1. Como mencionamos al inicio del artículo – El principal factor a tener en cuenta al diseñar una arquitectura rentable es la reducción de los datos escaneados por el usuario final.
2. En la mayoría de los casos, el usuario final resultará ser un analista o un usuario de negocios usando las consultas como una plataforma para Inteligencia de Negocios.
3. Queremos reducir la cantidad de datos tanto para reducir costos como también para mejorar el rendimiento.
No querrás que tu CEO tenga que esperar por sus datos más de algunos segundos.
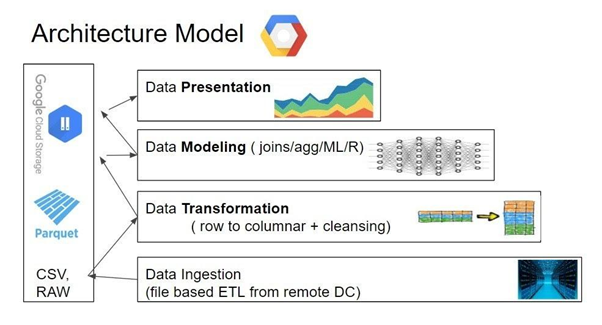
4. La manera de reducir los datos es un simple método por capas que empieza con datos crudos: La capa de ingestión. Y termina con una pequeña porción de datos diseñados y agrupados específicamente para la herramienta de BI de tu elección: La capa de presentación
5. En medio de estas capas debes realizar toda la limpieza, transformación, unión y agregación para así ayudar a la capa superior a tener consultas rápidas y baratas para tus visualizaciones de BI.
6. Recomendamos ampliamente el desacoplar tu procesamiento de tu almacenamiento. Una solución común para eso es el usar Airflow para orquestar todos tus procesos.
7. Las operaciones de datos en cada nivel pueden ser ejecutadas por alguna herramienta de tu elección. Una buena práctica para simplificar el proceso es empezar las implementaciones meramente con vistas internas.
8. Así es como se deberá ver eventualmente:
Traducido por Josue Padilla –Josue Padilla