
¿Por qué cada equipo de DevOps necesita un líder FinOps?
Conocemos en términos numéricos la cantidad de nuestro presupuesto que invertimos en tecnologías cloud, ¿pero sabemos realmente qué parte de este gasto es necesario o no? O desde otro nivel de pensamiento, ¿hasta qué punto podemos mejorar la eficiencia de nuestro gasto en estas tecnologías? Estas dos preguntas afectan a todos los equipos que hayan mudado parte de su infraestructura a la nube, y en el siguiente artículo,trataremos de responder a ellas, ya que en una desaceleración como la que sufrimos por la pandemia, todas nuestras inversiones deben ser óptimas para ayudarnos a mantener a nuestra compañía rentables, o en el peor de los casos, a flote.
En tanto que somos una startup en rápido crecimiento, en PerimeterX (la empresa en la que trabajo) ya empezamos a pensar en los modelos FinOps hace varios años, en cuanto nos dimos cuenta de que la inversión en infraestructura podría convertirse en una punto opaco que afectase significativamente a nuestro negocio, tanto positiva como negativamente. Todos dentro del sector DevOps hemos leído (y vivido) historias de terror sobre facturas astronómicas derivadas de un fallo del equipo de desarrollo, de alguien olvidando cerrar un cluster o de una respuesta de emergencia a un evento de escalado que no se desenvolviesedela forma correcta.La finalidad del FinOps es esta, prevenir este tipo de desastres, permitiendo así al equipo gestor analizar, ser reflexivos y plantear hipótesis al respecto de la interacción entre nuestros servicios cloud.
Bajo nuestra experiencia, la sorpresa de sumergirnos en estas preguntas fue que los desafíos FinOps nos abrieran los ojos a cómo unas buenas prácticas FinOps podían también llevarnos a una mejor experiencia de cliente y a un diseño de producto más inteligente.
¿Qué es FinOps?
Para algunos de vosotros este puede ser un concepto nuevo, por lo que empezaremos por ahí. Y para ello, la definición de la FinOps Foundation responde perfectamente a nuestra pregunta
“FinOps” es el modelo de operaciones para la cloud. Permite un cambio en la forma de pensar en este, una combinación de sistemas, buenas prácticas y cultura de trabajo que permitan a nuestra organización entender de forma analítica tanto nuestras inversiones como los costes de oportunidad derivados de estas. En el mismo sentido en el que el DevOps revolucionó el mundo del desarrollo echando abajo silos organizativos y desarrollándose de forma ágil, el FinOps incrementa el valor añadido de la cloud para nuestra organización,uniéndose así en un nuevo conjunto de procesos a profesionales de la tecnología, la gestión y las finanzas.
En pocas palabras, FinOps aplica los principios DevOps a la gestión financiera y operativa de activos e infraestructura cloud. Idealmente, lo que implicaría esto sería la gestión automatizada de estos activos a través de código en lugar de mediante intervenciones humanas. Para que esto sea efectivo, el profesional del FinOps debe entender cuáles son los patrones de uso de sus usuarios y los requisitos de su producto, y ser capaz también de construir un mapa que le permita maximizar valor mientras continúa optimizando la experiencia de cliente.
¿Cuál es el proceso de pensamiento FinOps en PerimeterX?
Comenzamos preguntándonos, “¿por qué estamos haciendo esto así?”. Una de nuestras razones era la posibilidad de ampliar márgenes y gestionar mejor nuestro gasto en la cloud, pero rápidamente nos dimos cuenta de que podríamos usar el FinOps para tener una visión más clara de nuestra filosofía en lo relativo a infraestructuras,y así ayudar a reducir la distancia entre nuestros equipos de desarrollo, de DevOps y de finanzas. Algunos de los problemas que ya habíamos detectado previamente y queríamos resolver eran:
- Nuestro equipo de desarrollo no siempre entendía las implicaciones financieras de sus decisiones sobre arquitectura.
- Los desafíos vigentes que existían al alinear los objetivos de optimización de costes del equipo de DevOps con respecto a las capacidades de nuestros nuevos productos.
- El equipo financiero usaba registros y facturas con uno o dos meses de antigüedad en su labor informativa para con los equipos de gestión, lo que hacía imposible que se tomasen decisiones correctas o se identificasen áreas de picos de gastos elevados de forma eficiente.
- La comunicación entre los equipos de desarrollo, DevOps y finanzas respecto a los gastos en curso y futuros era a menudo lenta e ineficaz. Debido a esto, llegamos a la conclusión de que adoptar un programa y una mentalidad FinOps podría poner a nuestros equipos en la misma sintonía, alinear sus puntos de vista y proporcionarles un framework compartido de métricas de seguimiento para los procesos diarios de toma de decisiones.
FinOps en acción en PerimeterX
PerimeterX es una empresa de seguridad SaaS que permite a las empresas proteger sus aplicaciones, apps móviles y APIs contra bots maliciosos o ataques skimming como Magecart. Nuestro centro de negocio y parte de nuestro equipo de ingeniería está ubicado en Silicon Valley, mientras que la mayor parte de nuestro equipo de desarrollo se encuentra en Israel.
Nuestro desafío, como hablamos, comenzó hace unos tres años como un intento de comprender, medir y administrar mejor nuestros gastos en la cloud. Sabíamos que, según fuéramos creciendo, optimizar nuestro gasto en la nube conllevaría un impacto material en nuestros márgenes brutos, así que de esta manera, nuestro desarrollo FinOps comenzó como un proyecto interno de I+D para crear herramientas que permitiesen gestionar y medir el gasto en la cloud en relación a la performance y uso de aplicaciones, o incluso en relación a los clientes individualizados. En PerimeterX tenemos varios equipos usando infraestructuras cloud, y a menudo desarrollamos productos en estas para satisfacer las necesidades de nuestros clientes. El equipo de ingeniería, el cual pertenece al de I+D, es la unidad encargada de crear este tipo de productos, y también es el encargado de investigar y desarrollar nuevas características. Una vez que se programa que una de estas características entren dentro de la hoja de ruta del producto, el equipo de ingeniería es quien se hace cargo de su desarrollo.
Cuando comenzó nuestro proceso de pensamiento FinOps, los únicos datos que teníamos para analizar eran totalmente planos y carecían de información clave o de un formato capaz de hacernos sacar conclusiones a partir de ellos, por lo que no teníamos medios de atribuir valores monetarios a proyectos o investigaciones específicas.Ya podréis imaginar la pesadilla que podía llegar a constituir esto.Para crear un punto de partida, enriquecimos manualmente los datos agregando estimaciones o aproximaciones de nuestros patrones de gasto en la cloud, y aunque los números no fuesen exactos, la forma de pensar respecto a este proceso ha venido siendo la misma desde entonces:
- Creación y mantenimiento de un balance en I+D y seguimiento del gasto mensual en investigación, despliegue y otros gastos derivados del I+D en la cloud, excluyendo de este el derivado despliegues de producción y funcionalidades de ventas y marketing.
- Construcción de modelos predictivos del gasto derivado de cada nueva funcionalidad producto a partir de variables clave como el tráfico o la ubicación del cliente.
De los archivos planos al Granular Cloud Service Tracking
En cuanto Google Cloud desplegó una funcionalidad para exportar de forma desglosada los detalles de facturación,que además permite conectarlo directamente a BigQuery, su base de datos para análisis, nuestro proceso tomó un punto de inflexión. Esta funcionalidad fue la Ilustración de nuestros desarrollos FinOps, gracias a los datos granularizados y enriquecidos que ahora podíamos obtener a partir de nuestros datos de uso en GCP.
Para nuestras métricas operacionales, nosotros ya habíamos implementado un etiquetado granular de cada proceso y servicio de nuestro sistema. Por ejemplo, cada instancia ya estaba siendo etiquetada con respecto al servicio que estaba hosteando, y así también estábamos haciendo con las instancias de bases de datos, tablas y buckets de almacenamiento. Además de esto, añadimos una funcionalidad que permitía el monitoreo de etiquetas que permitiese trackear tanto su latencia como su disponibilidad. En esencia, creamos un “SKU”, un código de inventario (por decirlo en términos de venta al por menor), para cada componente de nuestro sistema, para así mejorar los códigos de inventario que ya estábamos recibiendo de nuestro proveedor cloud. Este etiquetado facilitó el mapeo de uso del servicio, así como el de sus costes, eficiencias y disponibilidad, y la vinculación, de esta forma, del DevOps y su monitoreo operacional al modelado financiero de costes.Hasta aquí, nuestros procesos de optimización financiera estaban siendo construidos en torno a datos o métricas parcialmente precisas o simples, así como en torno a núcleos no auto escalados, memoria y capacidad de disco. Ahora, con el etiquetado enriquecido, BigQuery, y la integración de los datos de diferentes proveedores cloud que iban siendo actualizados frecuentemente, por fin podíamos realizar consultas al respecto del equilibrio entre rendimiento y costo. Así también empezamos a poder plantear y probar hipótesis con respecto a diferentes formas de atacar un mismo problema. A medida que crecimos y con ello nuestra exposición al riesgo derivado de los costes la cloud también lo hizo, esta capacidad nos fue dando una mejor visibilidad de las implicaciones de cada nueva funcionalidad del producto.
Explorando nuestro gasto en la cloud con una lente FinOps
En los primeros meses de 2019, cuando observamos nuestros costes de red usando nuestro nuevo microscopio FinOps (aka BigQuery), descubrimos algo que nos sorprendió. Habíamos añadido poco antes un servicio nuevo (llamémoslo “the syncr”) que usábamos para sincronizar algunos resultados computacionales a lo largo de varios de nuestros puntos de presencia (PoPs), ya que nos estábamos planteando la posibilidad de añadir más PoPs, por lo que primero queríamos saber algo más sobre los costes potenciales.
Mientras profundizábamos en este punto, descubrimos que la mayor parte de nuestros costes de red venían de nuestras redes interregionales, y así mismo estos de los servicios “syncr” (podéis ver los detalles en los gráficos 1 y 2 que mostramos abajo). Este descubrimiento hizo que el equipo que creó el syncr se plantease una revisión sobre su propio trabajo. Esta rápidamente descubrió una error que causaba que cada petición de sincronización se enviase dos veces. Puesto que el sistema había sido escrito para ser idempotente, esto no había causado ningún error de aplicación, y por ello este error no fue detectado hasta la revisión antes mencionada en torno a los costes de red desde una metodología FinOps.
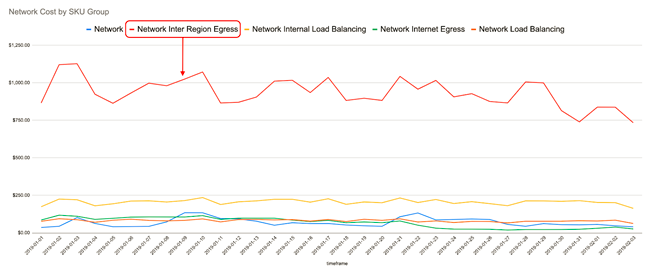
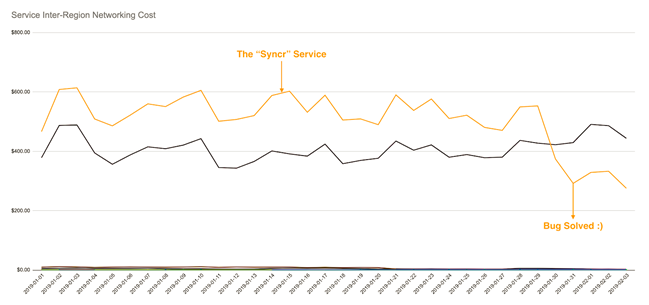
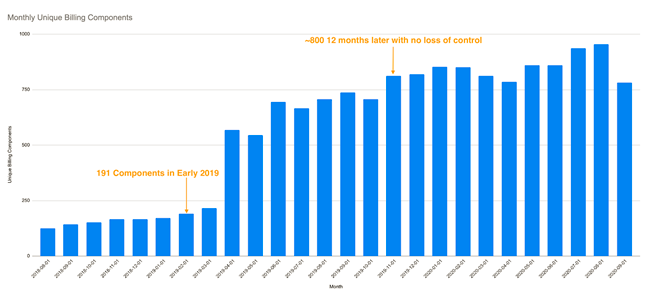
A estas alturas de 2019, nuestros equipos ya se habían encargado de desplegar y por lo tanto estaba gestionando unos 191 sistemas. Realizábamos cambios diarios en nuestros códigos, funcionalidades y configuraciones de cada servicio. En este punto fue en el que nos dimos cuenta de que sería productivo enseñar a más gente a gestionar sus modelos de costes en la cloud para asegurarnos de que estos tendrían en cuenta el impacto de los costes de despliegue de cada cambio. De esta manera seríamos plenamente reflexivos con respecto a nuestros propios modelos de costes, y así nos resultaría más sencillo agregar nuevas características y productos a nuestro porfolio.
Revisamos con cada equipo la composición de costes cloud (núcleos, memoria, redes…) para asegurarnos de que todos estábamos en sintonía con estos cambios. Tras ello, tuvimos sesiones específicas sobre mediciones de los diferentes equilibrios, como por ejemplo hosts interrumpibles (el equivalente de GCP a las instancias de spot en AWS) frente a otros tipos de instancias más caras, así como otro tipo de gotchas de costes cloud. Estas sesiones, como decimos, nos ayudaban a todos a entender mejor nuestra metodología FinOps, así como a crear una conciencia de equipo en torno a esta. A su vez, todo esto, así como las diferentes herramientas que habíamos puesto en marcha, ayudaron a todos los equipos a optimizar costes en relación a los diferentes objetivos y prioridades (rendimiento frente a coste. etc), y en definitiva, a generar más beneficios derivados de las buenas prácticas en la cloud.
Un excelente ejemplo de los frutos de nuestras sesiones FinOps apareció en febrero de 2020 cuando uno de nuestros equipos desplegó un nuevo servicio utilizando máquinas virtuales de Google Cloud. Tras otra ronda de sesiones formativas FinOps, los miembros de este equipo sugirieron que este servicio podría pasar a usar otros host menos costosos sin afectar al SLA del servicio. Esta transición redujo el coste del servicio en casi un 50% sin ningún impacto en la experiencia del cliente o las capacidades del producto.
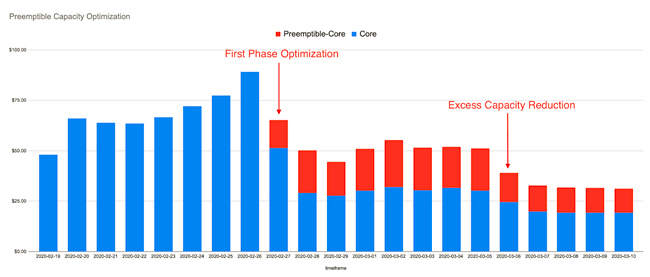
Para 2020 ya habíamos identificado la mayor parte de puntos débiles de nuestros esfuerzos de optimización basados en componentes, por lo que surgió un nuevo desafío: encontrar otras formas de ir hacia servicios más eficientes, lo cual nos indicó que necesitábamos aportar más dimensiones a nuestras herramientas FinOps, las cuales sabíamos que ningún proveedor cloud nos podría suministrar.
Como compañía SaaS multiplataforma, queríamos entender también cómo impactaba cada cliente en nuestro modelo de costes, y si era posible así mismo una optimización a nivel de cliente. Esto generó una segunda ola de ideas de optimización gracias a los defensores del modelo FinOps que habíamos hecho surgir en nuestro equipo y a las investigaciones que surgieron de estos. Ya habíamos implementado un ejemplo de lo que serían optimizaciones de enrutamiento para ciertos tipos de clientes y APIS, y aunque estas nunca fueron identificadas como un problema sistémico más amplio, mirándolo a nivel de cuenta se hizo evidente que en el enrutamiento de algunas llamadas específicas de APIs se podría hacer una optimización de costes sin llegar a afectar a nuestro SLA y a los tiempos de respuesta de cada implementación.
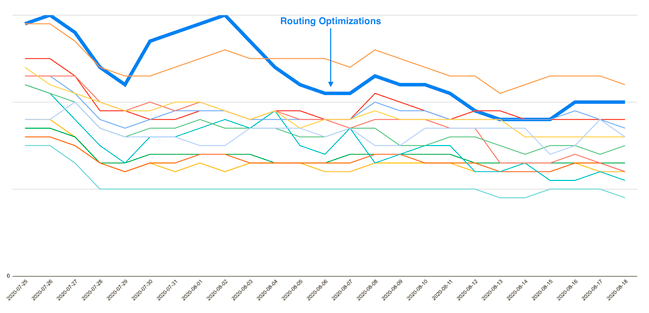
Como crear una conciencia FinOps en tu organización
Implantar el pensamiento FinOps en una empresa requiere también de cierta “ingeniería cultural” que impulse su adopción. Puedes ser el único experto en FinOps de tu organización, pero esto sólo funcionará hasta cierto punto. Para que este pensamiento sea realmente transformador, necesitas encontrar más compañeros interesados en el FinOps dentro de los equipos de Dev y DevOps, y para ello tendrás que facilitarles una ruta de aprendizaje.
Buscando embajadores y pioneros del FinOps
Como cualquier emprendedor ya sabe, formar un equipo es una de los factores cruciales para que una empresa triunfe. Si lo que quieres es maximizar las probabilidades de éxito de tu estrategia FinOps, tus compañeros deberán tener las siguientes cualidades:
- Curiosidad por cómo funciona una organización.
- Entender la importancia de la responsabilidad financiera dentro de una organización.
- Interés por el éxito de la propia compañía.
- Saber cómo funciona su sistema FinOps.
- Conocer cómo funcionan y cómo se comportan las arquitecturas cloud y sus estructuras de costos.
- Capacidad para tomar decisiones equilibradas a partir de puntos clave como costes, estabilidad, performance y otros marcadores.
- Capacidad de evangelización efectiva hacia una mentalidad FinOps, así como interés para unir a otros compañeros a la causa.
A medida que su práctica FinOps vaya madurando, irá viendo crecer su equipo de embajadores, ya sea de una forma orgánica (por su propio interés) o por el interés del resto de equipos en el tema. En buena medida en la misma forma que el DevOps, la gestión FinOps busca democratizar la responsabilidad financiera en lugar de encuadrarla dentro de unos feudos determinados. Esta será la única manera de escalar de forma efectiva y permanente esta práctica.
La efectividad del FinOps depende de su visibilidad
Tras crear dashboards básicos para las métricas clave de nuestro FinOps, comenzamos a publicarlos internamente y a compartirlos en las diferentes reuniones para ir dando feedback al resto del equipo respecto a qué era exactamente lo que estábamos haciendo. Y ojo, ya que publicarlo no es suficiente. Algunas de las cosas que sabíamos que necesitaríamos eran:
- Hacer una metodología, herramientas y experiencia de usuario FinOps que sean evidentemente útiles. Tanto como para ser uno de los MVP internos.
- Hacerlo procesable por los distintos equipos: Destacar las formas en las que estos podrían aprovechar la información que les damos para mejorar su estructura de costos, su diseño o el rendimiento de sus aplicaciones.
- Darle importancia: Demostrando el claro ahorro de costes que supone, desarrollando informes al respecto e incluyendo consideraciones FinOps dentro de la visión global de la empresa que tiene cada equipo.
- Crear objetivos: Así como cualquier otro KPI, asignamos objetivos y puntos de referencia porque aquello que es medible y cuantificable acaba siendo aquello a lo que se le da importancia por parte de los equipos.
Ya llevamos unos tres años en nuestros viaje FinOps y aún así seguimos encontrando diferentes oportunidades cada mes para ahorrar dinero o tomar mejores decisiones operativas, y aún más importante, esta “visión FinOps” se ha convertido en una parte fundamental de nuestra infraestructura y de nuestro proceso de diseño. En lugar de convertir el FinOps en un elemento a posteriori, al considerarlo ya como algo necesario al producto, somos capaces de tomar decisiones más inteligentes a largo plazo, que además, y no por casualidad, ayudar a mejorar la experiencia de nuestros clientes.
Dicho esto, ahora es vuestro turno, ¡nos encantaría escuchar los retos FinOps que se plantean en vuestra empresa!
Traducido por : Diego garcia acosta www.spainclouds.com/authors/diego-garcia-acosta