
Hoy empiezo con Kubernetes

Desde que te dije que iba a empezar con Docker, la verdad es que ya hemos recorrido un largo camino, pero todavía queda mucho por aprender. Si no has tenido oportunidad de ver los artículos anteriores creo que te pueden ayudar, si tu idea es empezar también con Kubernetes. Aquí te dejo el listado de lo visto hasta ahora:
- Hoy empiezo con Docker
- Publicar tu imagen en Docker Hub
- Publicar tu imagen de Docker en Azure Container Registry
- Ejecutar contenedores de Docker en Azure App Service
- Ejecutar aplicaciones multi-contenedor con docker-compose
- Gestionar los datos de tus contenedores de Docker
- Aplicaciones multi-contenedor en un clúster con Swarm
- Dockerizar tu aplicación Symfony
- Ejemplo de volumen en Docker
- Comunicar contenedores de Docker entre sí
- Azure CLI desde un contenedor Docker de usar y tirar
- Azure Container Instances: el servicio serverless para tus contenedores Docker
Hoy voy a empezar a ver contigo Kubernetes y quiero hacerlo con una breve descripción de qué es y cómo montar tu primer clúster en local ¡Empecemos!
¿Qué es Kubernetes?
Al igual que Docker Swarm, Kubernetes es un orquestador de contenedores, creado por Google, por lo que su trabajo es arrancar y parar aplicaciones basadas en contenedores. Además, es capaz de decidir por nosotros en qué parte del clúster pondrá nuestra aplicación y nos promete además abstracción de la infraestructura que hay por debajo. Por último existe un concepto llamado Desired State, que básicamente lo que dice es que podemos definir cómo debe de ser la arquitectura de nuestra aplicación y Kubernetes será el encargado de que la misma se cumpla. Esto ocurría también cuando te conté Swarm, con el archivo YAML, que especifica qué pinta tiene nuestra aplicación y este se encargaba de desplegarla en el clúster y mantener el número de replicas que habíamos elegido para esta.
Una de las mayores ventajas de usar Kubernetes es su rápidez tanto en despliegue como en recuperación, de ahí que se haya hecho tan famoso.
Al igual que ocurre con Swarm, en un clúster con Kubernetes tenemos dos roles: master, que es el que gestiona el clúster, y nodes, que son los que curran. En cada máquina hay un agente instalado llamado kubelet, que es el que se utiliza para que el master pueda comunicarse con los nodos. Según la documentación oficial, un clúster productivo debería de tener un mínimo de tres nodos.
Para este artículo voy a mostrarte cómo montar un clúster de Kubernetes en local utilizando VirtualBox, para que lo puedas hacer en el sistema operativo que quieras. Existen varias formas de instalarlo, por ejemplo:
- Utilizar Docker Desktop, el cual tiene la opción de habilitar Kubernetes (genial para desarrollo).
- kubeadm
- Desde cero. Existe una guía como referencia en esta página de GitHub: https://github.com/kelseyhightower/kubernetes-the-hard-way
- En la nube, que ya veremos más adelante.
Para este caso voy a utilizar kubeadm que hace mucho del trabajo por nosotros y además pretende seguir las buenas prácticas establecidas. No pretendo montar un entorno productivo, pero si ver qué es lo mínimo necesario para poder montar tu propio clúster.
Crear las máquinas virtuales en VirtualBox
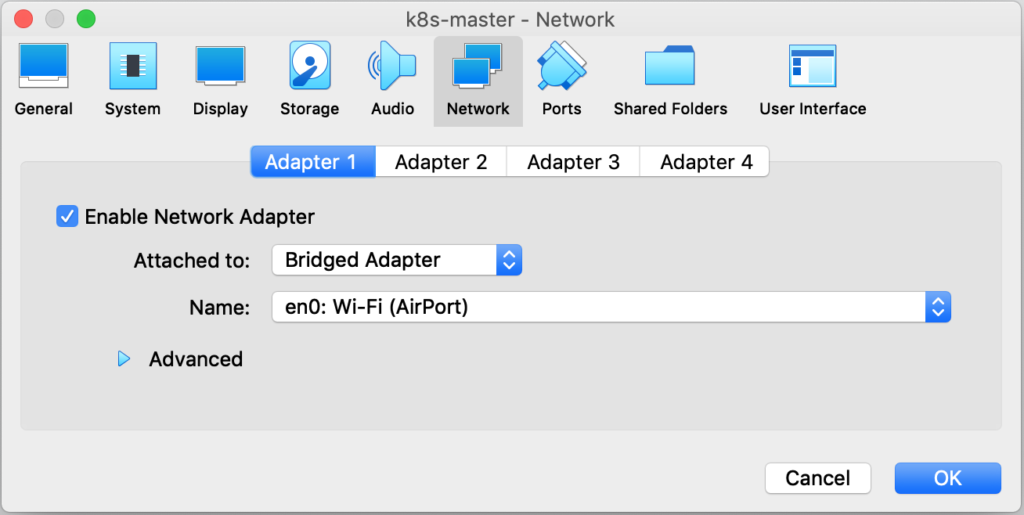
Para este ejemplo voy a utilizar 2 nodos (k8s-node1 y k8s-node2) y 1 máster (k8s-master) sobre VirtualBox. Me he descargado Ubuntu Server 18.04.2 LTS desde aquí. He modificado el tipo de adaptador a Bridge Adapter (Adaptador puente), en el apartado Settings > Network de cada máquina, para que las mismas pertenezcan a mi red local y así hacer más fácil el acceso.
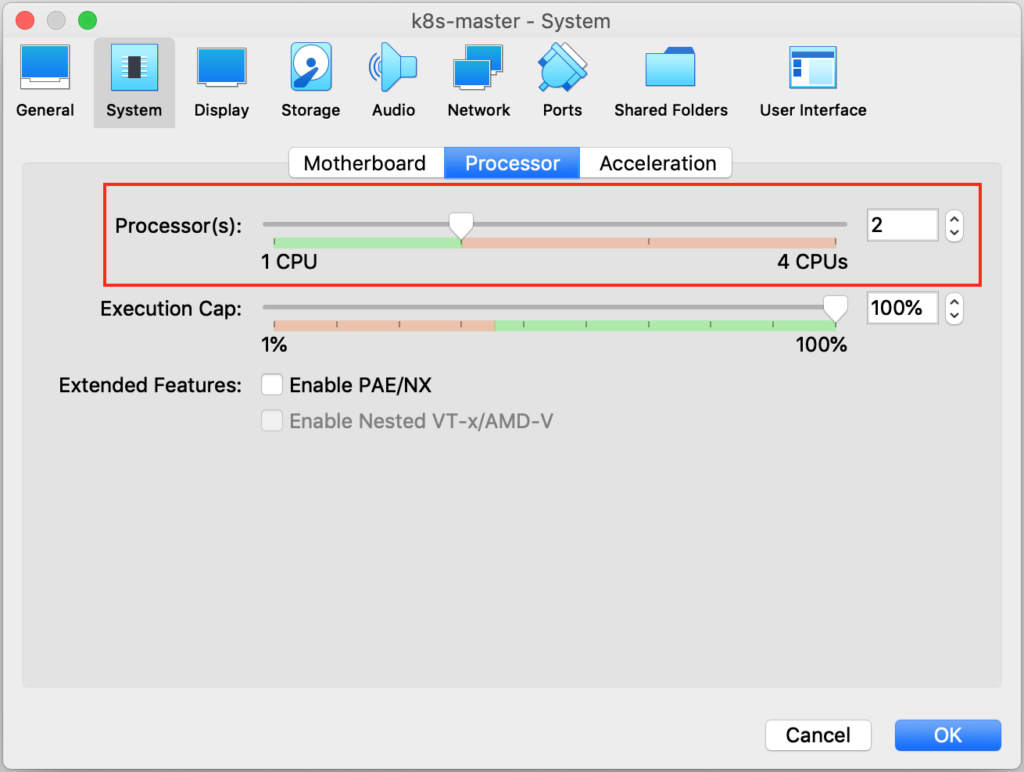
En la máquina que va a hacer de máster es importante que tenga 2GB de RAM y 2 cores, ya que sino en algún momento se quejará. Se puede modificar en Settings > System > Processor > 2 CPUs.
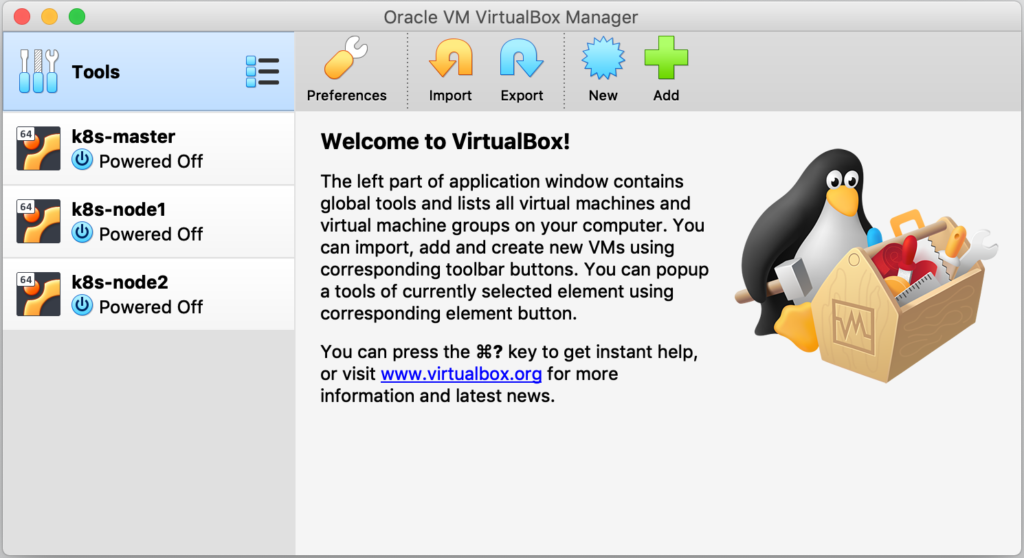
El resultado debería de ser el siguiente:
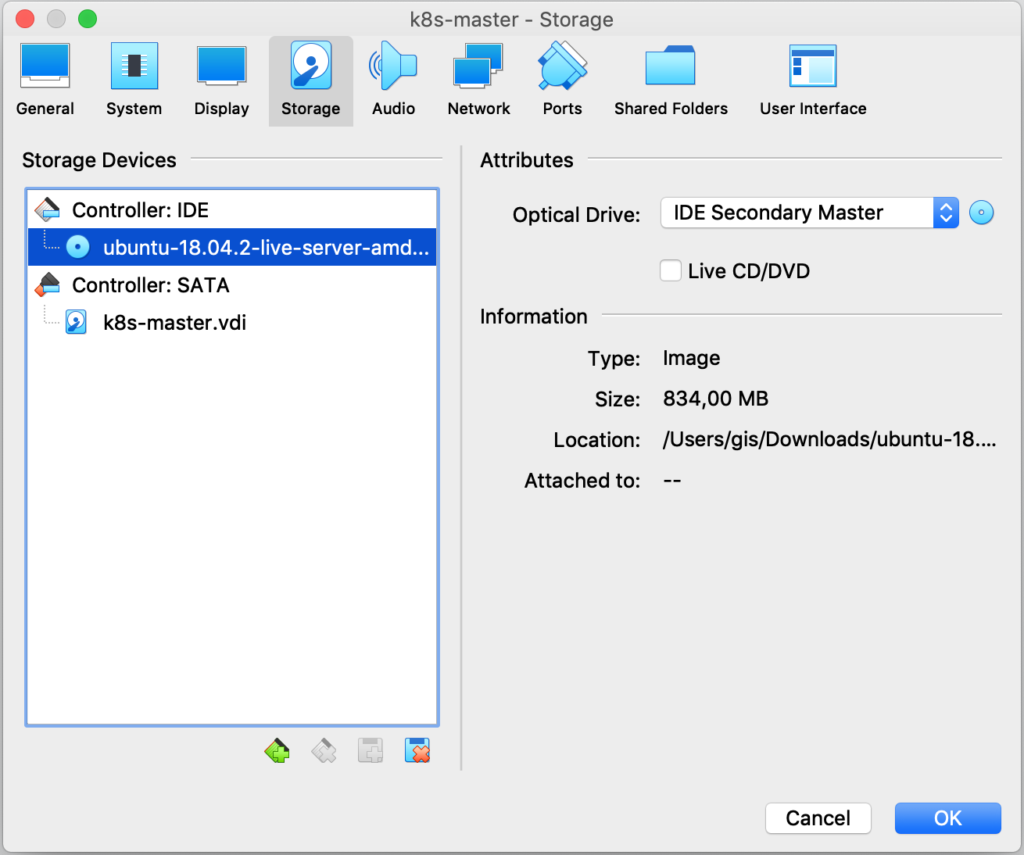
Por último, asocia la ISO de Ubuntu y comienza la instalación en cada una de las máquinas.
Durante la instalación, he utilizado los valores por defecto que se me iban ofreciendo en cada momento. Lo que sí he marcado es la instalación de OpenSSH server, para que lanzar comandos a mis máquinas sea más sencillo, ya que usaré Visual Studio Code como entorno de trabajo durante todo el artículo. En cuanto a la parte de Server Snaps no instales nada por defecto, que lo que queremos es aprender (aunque puedes ver que aparece docker, micro8ks, powershell, etcétera). Una vez que tus máquinas hayan terminado la instalación, anota sus IPs locales para poder acceder a ellas a través de SSH, aunque también puedes ir lanzando los pasos en cada una de las VMs directamente.
Para mantener las IPs estáticas de las máquinas debes modificar el archivo /etc/netplan/50-cloud-init.yaml en cada una de ellas. Aquí te dejo de ejemplo la configuración de mi máster.
# This file is generated from information provided by
# the datasource. Changes to it will not persist across an instance.
# To disable cloud-init's network configuration capabilities, write a file
# /etc/cloud/cloud.cfg.d/99-disable-network-config.cfg with the following:
# network: {config: disabled}
network:
ethernets:
enp0s3:
dhcp4: no
addresses: [192.168.1.51/24]
gateway4: 192.168.1.1
nameservers:
addresses: [8.8.8.8,8.8.4.4]
version: 2
Una vez modificado el archivo lanza el siguiente comando para aplicar los cambios:
sudo netplan apply
Nota: En entornos productivos las distribuciones que se suelen utilizar son Alpine Linux, Ubuntu Core o Container Linux.
Instalación de paquetes en las máquinas virtuales
Hay una serie de pasos que van a ser comunes tanto para la máquina que hará de máster como para los nodos, por lo que voy a paralelizar las tareas que hay que lanzar en todas y luego te muestro los pasos adicionales tanto en el master como en los nodos.
Pasos comunes
Lo primero que necesitas es deshabilitar el swap de todas las máquinas.
sudo swapoff -a
Comenta también en el fichero /etc/fstab la linea relacionada con el swap.
sudo vi /etc/fstab
Añade la clave para el repositorio de Google y el repositorio de Kubernetes a tu lista de repos.
Actualiza la lista de paquetes disponibles e instala docker, que será el tipo de contenedores que vamos a desplegar en nuestro clúster (Kubernetes acepta otros también), kubelet, kubeadm y kubectl.
sudo apt-get update
sudo apt-get install -y docker.io kubelet kubeadm kubectl
Marca además estos paquetes como “no actualizables”.
sudo apt-mark hold docker.io kubelet kubeadm kubectl
Para terminar, asegurate de que kubelet y docker se inician automáticamente cuando el sistema arranque.
sudo systemctl enable kubelet.service
sudo systemctl enable docker.service
Aquí puedes ver todos los pasos sobre el terminal:
Configuración del máster
El nodo máster es el encargado de iniciar el clúster y aquí es donde nos va a ayudar kubeadm. Antes de lanzar el siguiente comando ten en cuenta esto: cuando inicias el clúster vas a necesitar especificar un parámetro llamado –pod-network-cidr que, como su propio nombre indica, viene a decir cuál va a ser el CIDR que se va a utilizar para la red donde van a vivir los pods del clúster. Si no estás familiarizado/a con el concepto, simplemente es el rango de IPs que se van a asignar a tus aplicaciones según se vayan creando (lo veremos en el siguiente artículo). Este punto es muy importante ya que si no lo configuras bien puedes tener problemas de conflictos de IPs con la red donde está el host. Por ahora quédate con que este rango no puede ser el mismo que estás utilizando en tu red local. Por ejemplo, como en mi caso, si estoy en una red que trabaja en el rango 192.168.1.0, debo cambiar este a otro distinto, por ejemplo 10.0.0.0. Creo que es esta es la parte que más me ha costado entender de Kubernetes (y todavía sigo) que, si bien es potente, es un jaleo de IPs importante.
sudo kubeadm init --pod-network-cidr=10.0.0.0/16
Esta operación tardará unos instantes y finalmente te notificará de que el clúster se ha iniciado correctamente. Además, te mostrará el comando que los nodos deben lanzar para unirse al mismo.
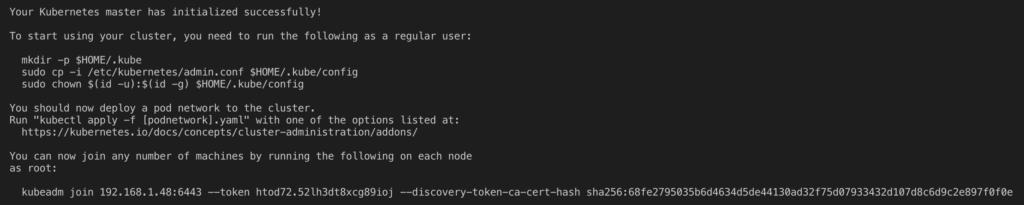
Como pone en el mensaje de salida, para poder empezar usar el clúster debes lanzar el siguiente comando con un usuario que no sea root.
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
Para finalizar con la configuración del máster, uno de los puntos más importantes que debes de decidir, antes de alojar tus apps en Kubernetes, es qué topología de red quieres. Para este ejemplo vamos a trabajar con el proyecto calico, por lo que necesitas descargar los siguientes archivos.
wget https://docs.projectcalico.org/v3.3/getting-started/kubernetes/installation/hosted/rbac-kdd.yaml
wget https://docs.projectcalico.org/v3.3/getting-started/kubernetes/installation/hosted/kubernetes-datastore/calico-networking/1.7/calico.yaml
El archivo calico.yaml utiliza por defecto el CIDR 192.168.0.0/16. Si estás en el mismo caso que yo, antes de aplicar la configuración que viene en dicho archivo, debes modificar el valor de la propiedad CALICO_IPV4POOL_CIDR para que coincida con el valor que has asignado a –pod-network-cidr.
Puedes acceder al archivo a través del terminal utilizando el editor vi.
vi calico.yaml
Y después debes buscar CALICO_IPV4POOL_CIDR y modificarlo a 10.0.0.0/16.
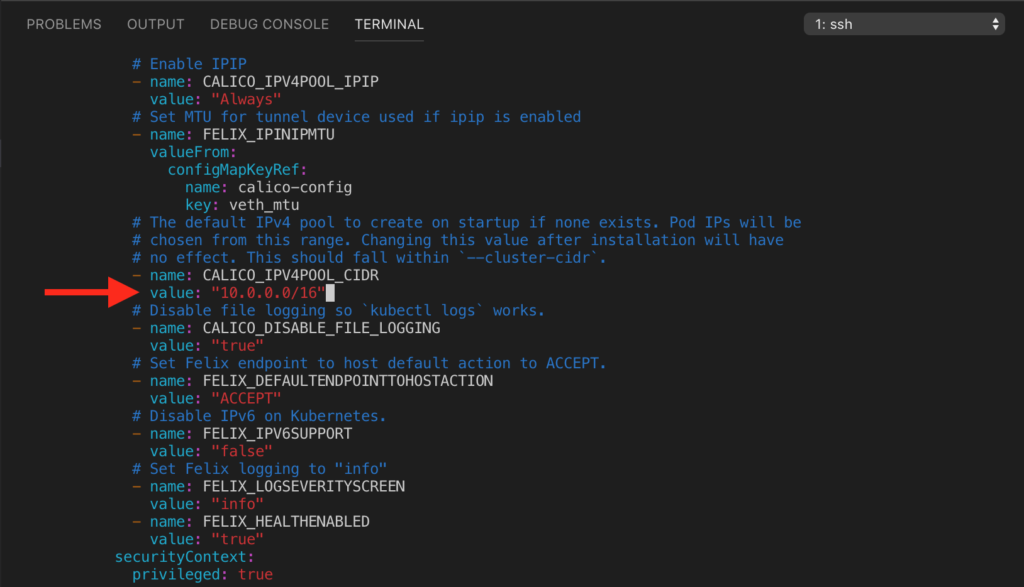
Utiliza estos dos ficheros para aplicarlos a tu clúster.
kubectl apply -f rbac-kdd.yaml
kubectl apply -f calico.yaml
¡Ya tienes tu clúster listo para empezar! Ahora vamos a por la configuración de los nodos.
Nodos
A parte de lo que vimos en el apartado de tareas comunes, lo que nos falta es añadir estas máquinas al clúster. Cuando lanzaste el comando kubeadm este te devolvió el comando que debías lanzar en los nodos para que estos se puedan unir. El comando será parecido al siguiente:
sudo kubeadm join 192.168.1.51:6443
--token dkvf4t.c87k9rfqz77co877
--discovery-token-ca-cert-hash sha256:9237727ee4a487faa76ba357c609a6b8bab2c69885689b6f4432054805dd6bcd
Cuando lo lances, en cada uno de los nodos obtendrás un mensaje como el siguiente:
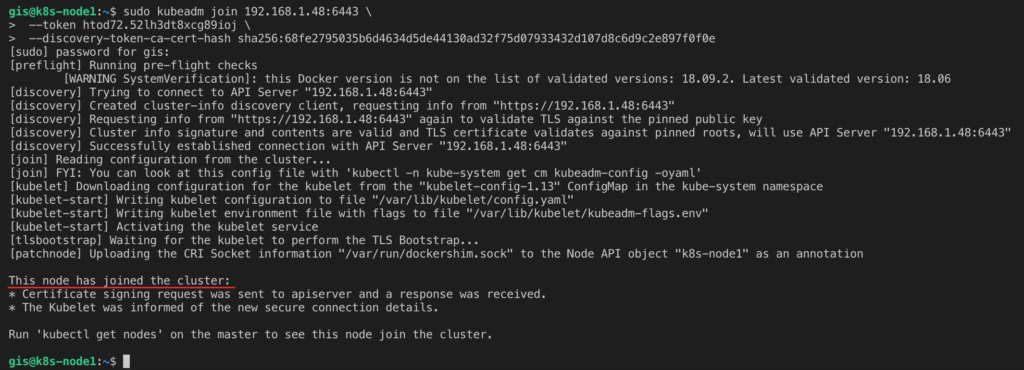
Comprobar que todo funciona correctamente
Ya tienes todas las máquinas configuradas y unidas al clúster. Esta configuración ha sido muy básica y muy por defecto pero creo que lo suficientemente buena para arrancar con Kubernetes. Para terminar este artículo puedes lanzar los siguientes comandos para ver que todo funciona correctamente:
#Get cluster information
kubectl cluster-info
#Get all nodes in the cluster
kubectl get nodes
#Get pods
kubectl get pods
En este video puedes ver el resultado de cada uno de los comandos.
En el próximo artículo veremos cómo se despliegan las aplicaciones en Kubernetes.
¡Saludos!