
Grabar streamings de audio con FFmpeg en AKS

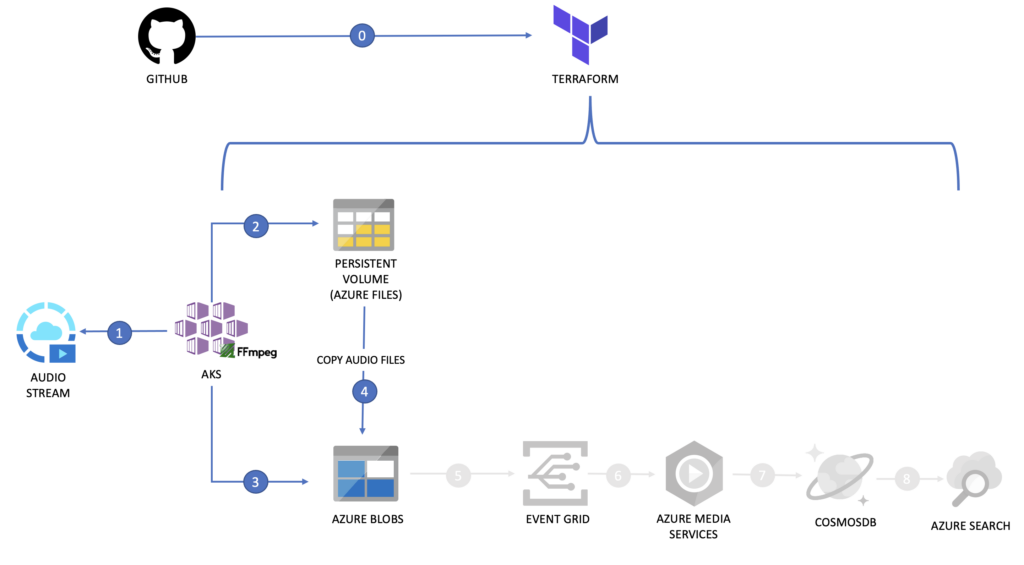
Grabar streamings de audio con ffmpeg en AKS
Además, una vez que los streams se van volcando a una cuenta de almacenamiento ltambién podríamos utilizar Azure Video Indexer, con el objetivo de obtener metadatos de forma rápida y sencilla de los assets que vamos recopilando, que es la parte que se ve en gris y que trataré en otro post.
En este artículo te cuento cómo llevar a cabo la primera parte, disponible ya en mi cuenta de mi GitHub.
Lo que queremos conseguir
Sin entrar todavía la parte de Docker, Kubernetes e incluso Azure, creo que es importante que entiendas qué es lo que quiero conseguir con esto: Imagínate que a día de hoy estoy grabando el contenido de diferentes audios que se están retransmitiendo en directo con la herramienta FFmpeg en mi local o una máquina virtual. El comando a utilizar sería parecido al siguiente:
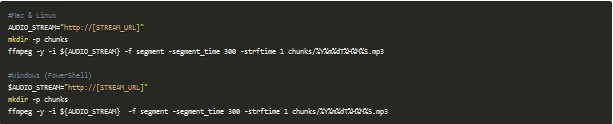
Si analizamos el comando anterior lo que tenemos es lo siguiente:
- -y se utiliza para forzar la sobrescritura de un archivo, en el caso de que exista y que FFmpeg no me pida confirmación.
- -i ${AUDIO_STREAM} define la entrada que va a recibir el comando.
- -f segment sirve para especificar qué tipo de archivo estamos generando. En este ejemplo estoy lanzando un comando que va a crear varios archivos cada cierto tiempo, por lo que es de tipo segmento.
- -segment_time 300 lo utilizamos para decir cada cuánto queremos crear esos segmentos, en segundos.
- -strtime 1 nos permite habilitar la posibilidad de utilizar el formato fecha de forma dinámica en el nombre de salida del archivo.
- chunks/%Y%m%dT%H%M%S.mp3 es el nombre que queremos darle a los archivos de salida. Como se van a ir generando archivo de manera automática cada 300 segundos, esto es cada 5 minutos, el nombre no debería de ser siempre el mismo para que no se machaque el contenido, por lo que utilizo el año, mes, día, hora, minuto y segundo para nombrarlos.
Si este mismo ejemplo quisiéramos llevarlo a un escenario con Docker, la foto no cambiaría mucho: en lugar de tener FFmpeg instalado en local usaríamos una imagen que tiene instalada la herramienta y solamente debemos decirle qué argumentos queremos utilizar:
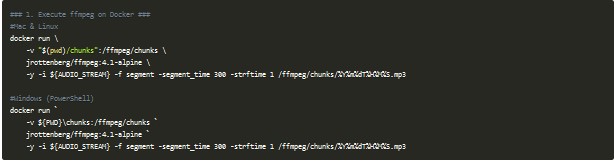
Como puedes observar, los parámetros utilizados son exactamente los mismos que si lo lanzara contra un FFmpeg instalado en mi máquina local.
Ahora que ya tenemos claro qué es lo que necesitamos lanzar, veamos cómo crear la arquitectura necesaria para esta prueba.
Terraform para desplegar la infraestructura
Para desplegar la infraestructura, podemos hacerlo a través del portal, con Azure CLI, o también puedes hacer uso de Terraform. Puedes revisar todos los archivos que he utilizado para ello en la carpeta terraform del repositorio. Para ejecutar el despliegue puedes hacer uso de los siguientes comandos:
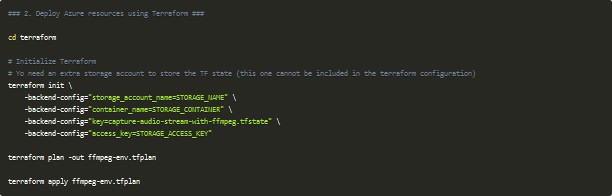
Date cuenta de que en mi ejemplo me estoy apoyando en Azure Storage para almacenar el tfstate, por lo que necesitas especificar los diferentes valores en el comando terraform init para que el estado de tu despliegue se persista en la cuenta que elijas.
Una vez que has lanzado todos estos comandos es necesario almacenar en variables los outputs generados para esta configuración, con el objetivo de poder utilizarlos en siguientes pasos:
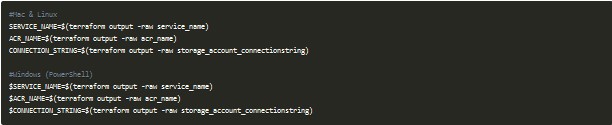
Lo que estamos guardando es el nombre del servicio asignado de manera aleatoria utilizando el recurso random_pet de Terraform, el nombre de nuestro Azure Container Registry, donde guardaremos una imagen, y la cadena de conexión de la cuenta de almacenamiento donde almacenaremos los audios finales.
Los recursos de Kubernetes
Para poder llevar a cabo todas las tareas que necesitamos, debemos crear los siguientes recursos de Kubernetes:
Secret para los datos sensibles
El dato más sensible que debemos compartir con otro de los recursos es la cadena de conexión de la cuenta de almacenamiento donde se almacenarán los audios. Para este tipo de información se recomienda el uso del recurso Secret:

El valor de los datos almacenados en un Secret deben estar en base 64 por lo que podemos convertir el contenido de CONNECTION_STRING, recuperado del despliegue de Terraform, con uno de estos dos comandos, dependiendo de tu sistema operativo:

Reemplaza el resultado en el archivo manifests/secret.yaml.
ConfigMap para las configuraciones de la grabación
Dentro del recurso ConfigMap voy a guardar los valores que quiero parametrizar para el Deployment y el CronJob:
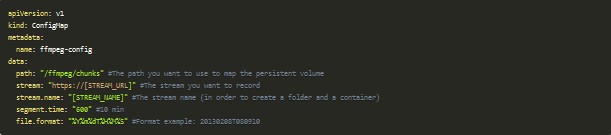
En este archivo, ubicado en manifests/config-map.yaml necesito cambiar el valor de stream por la URL de algún audio en directo y stream.name que será un nombre representativo para el mismo, y que veremos su utilidad después.
Si quisieras hacer la prueba pero no tienes ningún streaming de audio identificado te dejo algunos de ejemplo:
StorageClass para poder crear almacenamientos de tipo Azure File
Hace unos cuantos artículos atrás te estuve contando cómo AKS utiliza dos tipos de almacenamiento para los volúmenes persistentes, dependiendo del montaje que queramos utilizar en nuestro desarrollo. En este caso queremos usar un volumen que sea compartido entre múltiples pods, por lo que debemos hacer uso del tipo Azure File. La configuración de este se hace a través del recurso StorageClass como tienes a continuación:

Tal y como está definido en él, se utilizará para crear almacenamientos de tipo Azure File, con cuentas de Azure Storage de tipo Standard, con redundancia local. Además, nos permitirá expandir los volúmenes si fuera necesario.
PersistentVolumenClaim
Independientemente de si hacemos uso de Azure Files o Azure Disks para nuestros volumenes, necesitamos de un recurso más llamado PersistentVolumeClaim el cuál hará de pegamento entre la clase de almacenamiento y el pod:

Como puedes ver, en él hago uso de la StorageClass definida en el paso anterior, indico que será un volumen tanto de lectura como de escritura y que el espacio reservado debe ser de 10GB.
Deployment
El recurso clave de toda este prueba es el Deployment. En él es donde voy a definir cómo instanciar contenedores con FFmpeg y qué parámetros va a recibir este para hacer la captura de audio de un stream.
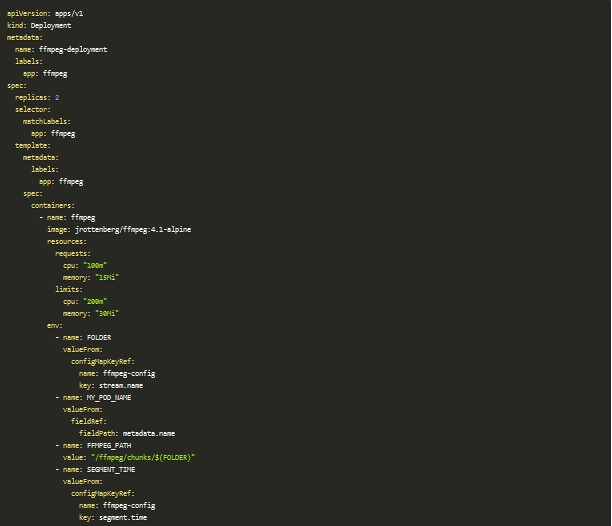
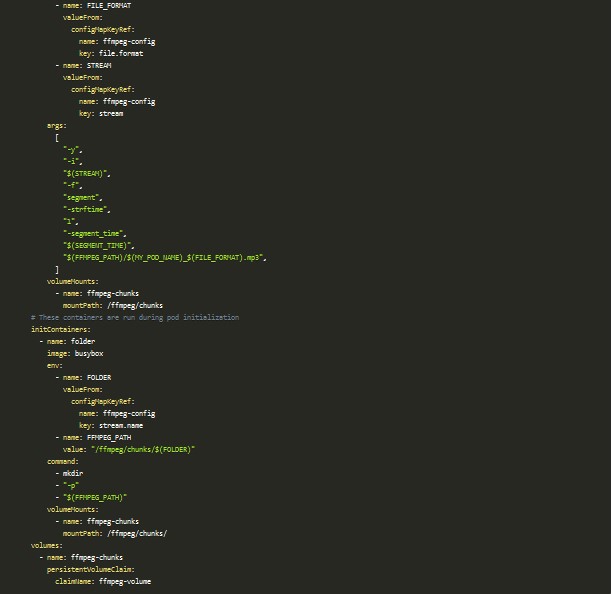
Si lo revisas con detenimiento, hay varios puntos importantes a tener en cuenta:
- Está configurado para que haya dos réplicas, o lo que es lo mismo dos pods, ejecutando FFmpeg con los mismos parámetros. Esto nos dará dos copias del mismo audio que posteriormente tendremos que decidir con cuál de las dos nos quedamos.
- Hace uso de dos contenedores: el primero de ellos es el que ejecutará el comando de FFmpeg con los parámetros obtenidos del ConfigMap y el segundo está incluido en el apartado llamado initContainers lo cual indica que es un contenedor que se lanzará antes de los contenedores principales, en la sección containers. Lo único que hace en este ejemplo es crear una carpeta dentro del volumen persistente con el nombre del stream que elegimos dentro del ConfigMap, para que todos los audios pertenecientes a un stream caigan dentro de esta. Como FFmpeg no puede crearla por sí solo utilizamos este mecanismo antes de que la herramienta comience a grabar.
- En el último apartado se especifican los volúmenes a usar, en este caso utilizamos el PersistentVolumeClaim definido anteriormente que hará que se cree si todavía no existe o que devuelva el que ya está creado.
Con este recurso conseguiremos que la herramienta estrella de esta prueba, FFmpeg, comience a grabar dos copias por stream, con el objetivo de que si uno de los pods se cae tengamos una segunda copia de respaldo y no perder minutos de grabación, pero ¿cuándo y cómo elijo qué archivos me quedo? Esta tarea la he delegado en un CronJob.
CronJob
Seguro que hay varias casuísticas que se me escaparon durante la prueba de concepto, pero solo es eso, una prueba Para poder determinar de esas dos copias con cuál me quedo he utilizado una tarea programada a través del recurso CronJob. Gracias a este puedo lanzar cada X minutos un proceso que compruebe si tengo segmentos de mi audio ya grabados, y finalizados, y decidir con qué copia me quedo de las presentes.
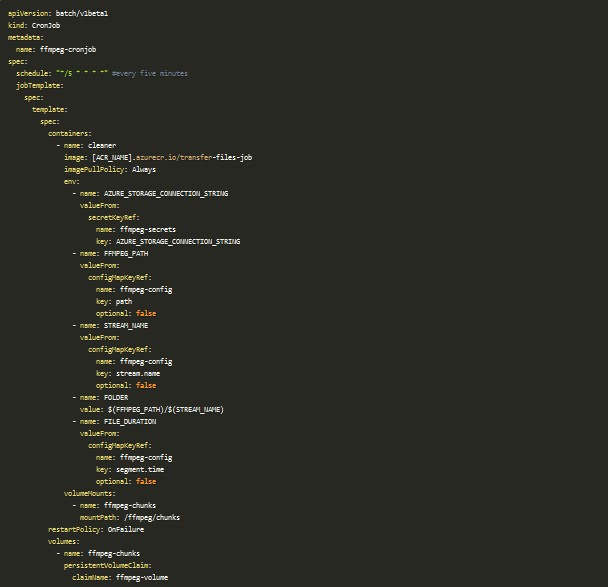
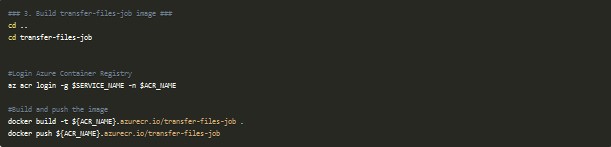
En este ejemplo lanzo un job cada 5 minutos que va a crear un pod con un contenedor llamado cleaner. Este se apoya en una imagen que contiene una aplicación en Node.js ubicada en el directorio transfer-files-job. Esta lo que hace es recorrerse la carpeta donde están grabándose los audios para el stream en cuestión, recopila todos aquellos que han terminado (es decir, que tienen una duración ya de 10 minutos) y se queda como candidatos aquellos que están más cerca de la fecha actual o del último archivo que se guardó, que está quedando registrado en una tabla de Azure Storage. Una vez que ha finalizado todas las comprobaciones, y ha copiado los archivos elegidos a la cuenta de almacenamiento, elimina las copias que ya ha procesado y deja las que todavía se están grabando. En este paso es necesario generar la imagen y subirla al Azure Container Registry, creado a través de Terraform:
Ahora que ya te he mencionado todos los recursos utilizados en esta prueba de concepto, y has ido modificando lo necesario para adecuarlo a tu entorno, puedes lanzar la creación de todos los recursos con el siguiente comando:

Durante unos instantes los pods se quedarán pendientes de inicializarse, debido a la creación de la cuenta de Azure Storage donde AKS creará la carpeta compartida que utilizarán como volumen los pods en un formato File Share. Una vez que esto ocurra los pods comenzarán a grabar el stream de audio elegido:
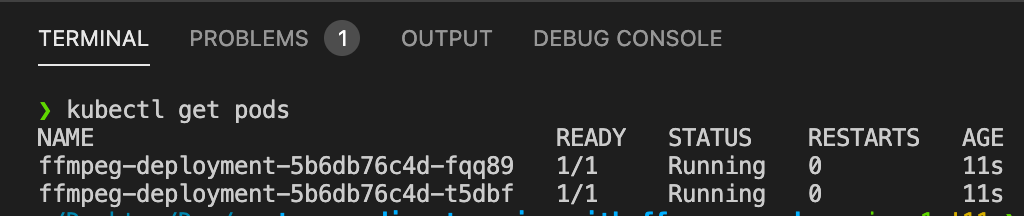
FFmpeg ejecutándose en AKS
Pasados cinco minutos podrás ver que el CronJob comienza a ejecutarse para comprobar si existe algún archivo de audio que cumpla dos condiciones para esta prueba:
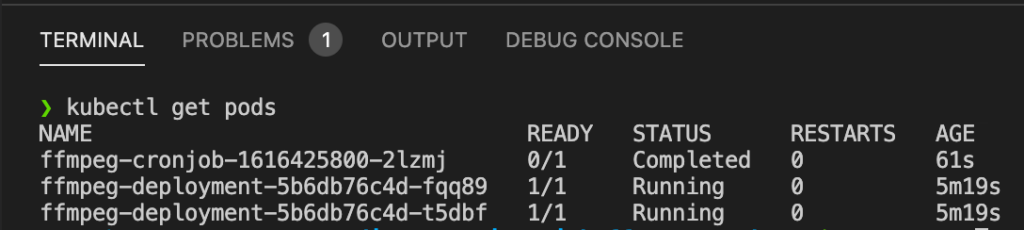
CronJob cada 5 minutos
Y pasados diez minutos podrás ver cómo los archivos se van almacenando en la cuenta de almacenamiento.
Plantilla con Helm
Si todo lo anterior quieres repetirlo por más de un stream, he creado un Chart de Helm que te permite lanzar el proceso de una forma sencilla, parametrizando el nombre que le damos al stream y la URL desde la que queremos grabar el audio. La forma de lanzarlo sería la siguiente:

Nota: en este caso no es necesario que se codifique la cadena de conexión a base64 ya que en Helm puedes usar una función que hace el trabajo por ti, llamada b64enc, como puedes ver en la plantilla utilizada para el secret.
¡Saludos!