

DynamoDB: optimizacion y diseño.
DynamoDB icon [4]
La evolución de la construcción de software con las nuevas implementaciones de tecnologías Cloud están significando un desafío para los equipos. Las construcciones o migraciones de proyectos a la arquitectura de microservicios significan un reto para ciertos aspectos de confiabilidad y performance a nivel de acceso a datos. Es aquí donde la elección del tipo de base de datos y la forma en la que se acceden los las tablas juegan un papel fundamental.
Mientras tanto, las opciones de bases de datos noSQL están tomando auge en la elección de modelos perfomantes. Si bien este tipo de bases no garantizan en su totalidad las propiedades ACID suelen tener una buena respuesta cuando se necesita escalabilidad.
DynamoDb es un servicio de gestión de base de datos no relacionales provista por Amazon. Cumple con las características fundamentales de una base de datos noSQL ademas de otros beneficios que permiten un mejor manejo de nuestros datos. Sin embargo, para sacar el máximo provecho DynamoDB, hay puntos que tener en cuenta a la hora del diseño de nuestra base de datos.
Luego de investigar y leer documentación, hubieron dos puntos que llamaron mi atención y del cual, a modo de recopilación de información, detallare a continuación. Estos dos puntos son la complementación de única tabla y el uso de caché DAX. El primero impacta sobre la etapa de diseño y la otra sobre la etapa de diseño e implementación.
Implementación de un esquema de única tabla.
La implementacion de base de datos relacionales, considera las tareas de normalizacion y aprovisionamiento de esquemas relacionales aportando tablas para cada entidad. Para ver esto supongamos un ejemplo una tabla de Alumnos y una tabla de notas de evaluaciones.
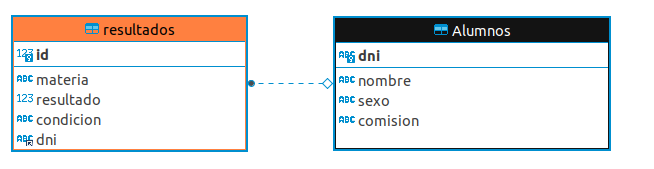
Basándome en el ejemplo que provee [2], hice la prueba con dos entidades diferentes. Supongamos que queremos obtener los datos de aquellos alumnos que han aprobado cualquier materia (esto es, obtener una nota mayor o igual a 6). Esto se traduce en la siguiente operación:
SELECT a.nombre from resultados r INNER JOIN Alumnos a ON a.dni = r.dni WHERE r.resultado >= 6;
La operación JOIN nos permitirá traer las dos tablas, interseccionar aquellos datos comunes entre las dos tablas dependiendo de algún atributo similar. Detrás de escena esto significara, traer el la tabla alumnos ,luego traer la tabla notas y luego proyectar los datos deseados. Esto significa 1ut (unidad de tiempo) para traer la tabla alumnos, otra 1ut para traer la tabla notas y dependiendo la operación, otra unidad de tiempo mas (o mas). A pesar de que la consulta JOIN puede usar optimizaciones para disminuir su tiempo de consulta y también aprovechar la cache de consultas, el requerimiento de lectura de n tablas sigue siendo poco beneficioso para consultas que necesitan rapidez y escalabilidad.
El esquema de uso de única tabla en DynamoDB [2], nos habilita la convivencia heterogénea de datos pero a la vista de optimizacion significa extraer la tabla por medio de una consulta. Esto significa una mejora cuando se trata de gran cantidad de datos y donde la escalabilidad es un requerimiento fundamental. Esto aprovecha y explota la capacidad de extraer datos en una sola solicitud, sumado a la implementacion de caches como DAX significan un gran punto de aprovechamiento a la hora de ejecutar aplicaciones que necesitan latencia minima.
La desventaja que provee esto, es que la curva de aprendizaje es alta, ya que se viene de bases de datos estructuradas , en donde la implementacion de normalizaciones y esquemas de diseños de base de datos permiten llegar a las operaciones que podemos realizar para obtener ciertos resultados. DynamoDB cambia la forma de pensar, ya que los diseños de estas tablas deben estar orientados al pensamiento ¿que necesitamos?. Esta pregunta a la hora de modelar nos permitirá descubrir cuales serán nuestros indices locales (LSI) e indices globales (GSI).
Sin embargo segun Debrie [2] no recomienda el esquema de única tabla cuando “Los beneficios no superen los costos ”. Por lo cual, realizar un buen estudio previo de la realidad a modelar nos permitira descubrir cuando este esquema puede ser explotado en su totalidad para aprovechar su principal beneficio.
Implementación de caché (DAX)
DynamoDb cuenta con un servicio de caché llamado Dynamo accelerator (DAX)[1]. Este servicio está formado por dos memorias caché ubicadas entre la base de datos y el cliente (la cache de elementos y cache de consultas). El funcionamiento es básico y cuenta con los siguientes pasos:
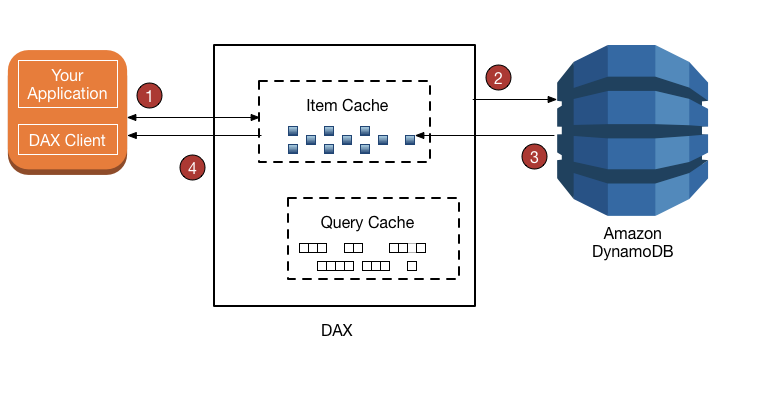
Figura 1: DAX dynamo db
- Para el par clave valor dado ,se busca en la memoria Cache. En caso de ser exitoso ,devuelve el valor (4).
- En caso de no ser exitoso, el valor se busca en la base DynamoDb
- El valor es recuperado y servido al usuario.
- Si el clúster de DAX contiene más de un nodo, el elemento se replica en todos los demás nodos del clúster.
Una vez que el dato es recuperado y almacenado en cache el tiempo de vida definido para cada items (TTL) es de 5 minutos. Se agrega una marca temporal a cada elemento y si vence el TTL el elemento es eliminado. Ademas, DAX tambien utiliza el algoritmo del menos usado (LRU), el cual elimina los elementos mas antiguos dando espacio a nuevas escrituras para elementos potencialmente entrantes.
Esta implementación es muy útil a la hora de tener acceso a datos frecuentes, y en términos de latencia significa una mejora en los tiempos de respuesta, el cual está condicionado por la probabilidad de acierto de una lectura a la caché. Ahora bien, la desventaja que posee esto es que si no son datos que se acceden frecuentemente se suma algunas unidades tiempo de respuesta debido al no acierto en la caché y búsqueda en la base de datos. DynamoDb provee dos esquemas para el almacenamiento de datos en caché, carga diferida (lazy load) y carga anticipadas (Read-through)
- Carga diferida: en este caso, el par clave valor es buscado en la memoria caché, si se produce un acierto el dato es devuelto. Caso contrario se busca en la base de datos ,se extrae el dato y posteriormente es almacenado en la memoria caché. En este caso, si para este dato el acceso es frecuente, significara menor tiempo de respuesta. Por contraparte ,tiene la desventaja que penaliza en la lectura de la primera lectura.
- Carga anticipada: Este esquema mantiene la tabla coherente. Cuando se modifica o escribe un dato, no solamente es modificada en cache sino que también es almacenado en la tabla principal. Con esto los datos recientemente modificados son mantenidos en cache, lo cual si existen busquedas para este dato, el mismo estara disponible en la cache. Son utiles en escenarios donde las escrituras son seguidas por una operacion de lectura. Este esquema tiene una sobrecarga de latencia pero se gana coherencia de datos en la cache.
Estos esquemas básicos de cache presentados aquí y provistos por DynamoDb son útiles para poder seleccionar esquemas de optimizacion para este tipos de bases de datos sin embargo hay algunos puntos a tener en cuenta.
- Consistencia de lectura: Supongamos que una aplicación A quiere hacer una operación getItem de una tabla. El dato se busca en la cache, el cual hace que se produzca un desacierto, por consiguiente este dato se busca en la tabla DynamoDb, es devuelto y almacenado en la cache. Posteriormente la aplicación A seguirá leyendo estos datos de la cache hasta que se venza su TTL o el algoritmo LRU lo desaloje. Supongamos ahora, que otra aplicación B escribió una actualización directamente a la base Dynamo (Evitando DAX) del dato recuperado por A un momento después de la lectura de dicho dato, entonces la aplicación A tendrá el dato totalmente incoherente hasta la próxima vez que necesite ser recuperado.
- Consistencia de escritura: DynamoDB utiliza un modelo de escritura (write-through), es decir, ante operaciones de actualizacion los datos se actualizan tanto en la cache DAX como en la tabla DynamoDB. Para entender esto supongamos que una aplicación hace una operación getItem de una table “Table-1”, en este momento la tabla tiene un atributo “Attr-1” con el valor 30, y este dato es almacenado en la cache DAX. Un momento después otra aplicación B modifica el valor de “Attr-1” con el valor 32. Si alguien no modifica este valor nuevamente, este valor tendra el valor 32 para todas las posteriores lecturas.
Si bien el tema de cache es ampliamente extenso y hay que tener otros items mas en cuenta descripto en [1] (se recomienda una lectura profunda), para esta entrada solo detalle algunos puntos que me parecieron interesantes para tener en cuenta a la hora de diseñar una base de datos no relacional que sea perfomante.
Conclusión
Optar por bases de datos no relacionales pueden ser una gran ventaja en ciertos escenarios. Estos escenarios deben estudiarse de manera profunda para entender si los esquemas de unica tabla pueden ser utilizados a fin de reducir latencia y si la utilizacion de cache DAX podria ser de utilidad para aumentar las prestaciones. Explotar ciertas caracteristicas de este tipo de bases pueden ser altamente beneficiosas en escenarios que se necesiten escalabilidad. Por el contrario, adoptarlas en otros escenarios que no son congruentes con lo descrito anteriormente, podría ser contraproducente y perder caracteristicas a costa de otros beneficios. Sin duda, adentrarse en el estudio y prueba de estas soluciones como DynamoDB, podría ser beneficioso para soluciones que necesitan escalabilidad, confiabilidad y rapidez.
Bibliografia
[1]https://docs.aws.amazon.com/es_es/amazondynamodb/latest/developerguide/DAX.consistency.html
[2] https://www.alexdebrie.com/posts/dynamodb-single-table/