
De qué manera AppsFlyer usa Apache Airflow para ejecutar más de 3.5k trabajos diarios

Technology geek ansioso por aprender cosas nuevas. Intentando crear cosas interesantes para la plataforma de datos AppsFlyer.
Lectura de 8 minutos

Operación real del flujo de AirFlow de AppsFlyer
AppsFlyer es esencialmente una compañía de Big Data, recibimos grandes cantidades de datos diariamente de nuestros SDK, transformamos y normalizamos estos datos, y luego los presentamos en nuestro panel con diferentes métricas y conjuntos de información que son relevantes para nuestros usuarios, ¿bastante básico, verdad?
Las cosas se vuelven cada vez más complejas cuando se le da contexto al volumen de los eventos, y en nuestro caso, estamos hablando de más de 90B de eventos diarios y alrededor de 200TB de datos diarios que se ingieren en nuestro sistema a AWS S3.
A fin de procesar y calcular todos estos eventos, AppsFlyer mantiene alrededor de 50 clústeres de Hadoop (Vanilla con un sistema de autoescalado interno) que ejecuta más de 3.5k + trabajos diarios de Spark que dividen, cortan y giran los datos para darles a nuestros clientes los datos más precisos que necesiten.
Una de las tecnologías principales que permite y respalda esta escala de operaciones de datos es Apache Airflow, que programa y ejecuta todos estos trabajos, a través de los diversos grupos, a la vez que conoce las diferentes características de cada trabajo.
En pocas palabras, ¿Qué es Apache Airflow?
En la documentación:
Airflow es una plataforma para crear, programar y monitorear programáticamente flujos de trabajo.
Use Airflow para crear flujos de trabajo como Grafos Acíclicos Dirigidos (DAG) de tareas. El planificador de Airflow ejecuta sus tareas en una matriz de trabajadores mientras sigue las dependencias especificadas. Las utilidades de la línea de comandos facilitan la realización de cirugías complejas en DAG. La rica interfaz de usuario facilita la visualización de pipelines que se ejecutan en producción, supervisa el progreso y soluciona problemas cuando sea necesario.
Cuando los flujos de trabajo se definen como código, se vuelven más fáciles de mantener, versionables, comprobables y colaborativos.
Piensa en Airflow como un servidor cron, pero con muchas funcionalidades como el diseño de flujos de trabajo, que son totalmente personalizables con una buena interfaz de usuario junto con el logging centralizado.
Arquitectura de Airflow en AppsFlyer:
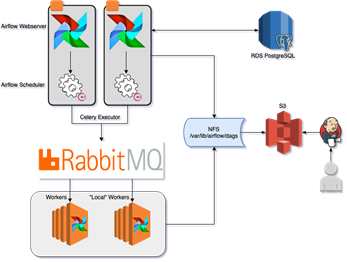
AirFlow es crucial para el negocio principal de AppsFlyer, ya que aquí es donde se ejecuta la gran mayoría de nuestras tareas de ETL, así como muchas otras. Con esto en mente, tuvimos que adoptar un primer enfoque de estabilidad y nos aseguramos de que cada parte de Airflow esté altamente disponible:
- Para la base de datos de metadatos, utilizamos PostgreSQL que es administrable, se respalda y tiene una réplica de lectura de respaldo a través del servicio AWS RDS.
- Los servidores web de Airflow se ejecutan en varias instancias, con Consul como balanceador de carga para distribuir las solicitudes entre ellos.
- En AirFlow, el planificador es el único componente que no está diseñado para alta disponibiliad, eso lo logramos solucionar usando los bloqueos de Consul. Ejecutamos el proceso del planificador con el comando de bloqueo. De esta manera, nos aseguramos de que solo una instancia del planificador esté activa, y si la instancia falla, se libera el bloqueo que luego activará otro servidor para reiniciar el servicio.
- Utilizamos CeleryExecutor con un backend RabbitMQ como ejecutor, de esta manera podemos hacer girar múltiples máquinas de trabajo, con un propósito diferente (separadas por la cola). Además, RabbitMQ es un clúster de alta disponibilidad en sí mismo.
- Para asegurarnos de que los trabajadores, el planificador y los servidores web se ejecutan con los mismos archivos, montamos un NFS entre todos los componentes. Este NFS es el objetivo del trabajo de Jenkins que usamos para implementar cualquier cambio (lo explicaremos más adelante).
Como se mencionó anteriormente, damos soporte a alrededor de 50 clústeres de Hadoop diferentes, y todas las versiones de Spark desde 1.6, para esto creamos nuestro propio SparkOperator que recibe los datos requeridos como parámetro.

Además del operador real que ejecuta el trabajo de Spark, tenemos muchos más operadores que se utilizan para escalar nuestros clústeres, ya sean nodos spot EC2 o bajo demanda para poder ejecutar la tarea real.
Esto es el resultado de aprender que, como subproducto de la administración de los clústeres de Hadoop, a menudo descubrimos que uno de los clústeres no funciona correctamente y necesita redirigir todos los trabajos del que funciona mal a un clúster diferente. Para hacer esto posible, creamos una forma de anular el parámetro real hadoop_cluster que el usuario ingresa en tiempo de ejecución, esto se hace a través de un diccionario que ingresamos como una variable de AirFlow que se ve así:

Este diccionario señala que el clúster «010» se cambió a «110», y cada trabajo que se suponía que debía ejecutarse en «010» se ejecutará en «110»
Operador Docker
Dividimos nuestras tareas ejecutadas en dos cargas de trabajo diferentes:
- Tareas que requieren recursos externos para ejecutarse, por ejemplo, Spark ejecutándose en modo de clúster. Estas tareas de envío se ejecutan con una baja cantidad de recursos locales, ya que estamos ejecutando todo en modo de implementación en el cluster.
- Tareas que requieren recursos locales, como computación, memoria o almacenamiento.
Estas dos cargas de trabajo son complejas cuando se ejecutan en una sola instancia, y es por eso que entendimos que necesitábamos crear un aislamiento completo. Afortunadamente, el hecho de que usemos CeleryExecutor introdujo una ventaja adicional. Creamos dos conjuntos de trabajadores de Airflow, donde cada uno escucha su propia cola. Un conjunto de máquinas es de tipo general, y el segundo tiene más recursos informáticos.
Debido a que AppsFlyer ya había invertido mucho en servicios técnicos que se incluyen dentro de un contenedor Docker, era un hecho utilizar también esta pila tecnológica preparada en Airflow.
Una vez que se construye un repositorio en Jenkins, el código se coloca automáticamente en contenedores y se carga en Artifactory. A partir de ahí, utilizamos un operador Docker construido internamente, que nos permite obtener y ejecutar estos contenedores dentro de los trabajadores de Airflow. Otro beneficio que obtenemos de esto es el hecho de que todos los recursos necesarios y las dependencias de código, como paquetes, módulos y otros recursos, ya están empaquetados dentro de la imagen de Docker, y no necesitamos instalar nada en los trabajadores.
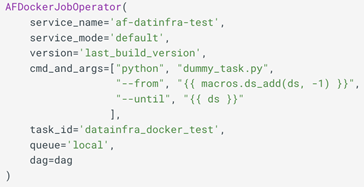
Operador Docker, ten en cuenta que el parámetro de cola es diferente entre AfDockerJobOperator y SparkOperatorWithHook en la sección anterior
Variables AirFlow
Las Variables Airflow, son un almacén de valores clave dentro de la base de datos de metadatos de Airflow. A AppsFlyer le encanta la flexibilidad que proporcionan, las usamos para almacenar parámetros comunes para múltiples trabajos, especificando el número de nodos en un clúster específico (para los operadores de escalado), la reutilización de los frascos de uso común … Realmente las usamos en todas partes . Por eso, no es una verdadera sorpresa que hayamos tenido varios problemas de producción directamente relacionados con cambios en las variables. Donde lo que nos falta es la auditoría, la validación y el CI adecuados para comprender si el cambio de variable rompe el DAG.
Esta fue otra oportunidad para construirlo nosotros mismos. Para realizar esta tarea, primero agregamos la autenticación LDAP al servidor web Airflow. Al hacerlo, nos permitió separar a los usuarios en función de los grupos LDAP, decidimos que los usuarios normales no podrán ver la página Admin (user_filter en la configuración de Airflow), pero esto también creó el subproducto no deseado de eliminar la vista de la página Variables. Para que el flujo sea más fácil de usar, creamos una nueva pestaña en la interfaz de usuario y agregamos una sección de solo lectura para las variables.

Los cambios en las variables se realizan desde un repositorio de Git e invocamos una canalización de implementación que actualiza la base de datos de metadatos con las últimas variables. El hecho de que sea de un repositorio de Git nos permite auditar, revertir y ver los cambios fácilmente.
Workflow de desarrollo
En AppsFlyer, nuestro objetivo es brindar al desarrollador una experiencia más simple y transparente. Para hacerlo, nuestro código operador está dentro de un directorio común tal como la definición del DAG, para proporcionar una transaprencia total del código de «infraestructura».
Una vez que los desarrolladores realizan cambios en su computadora local, pueden activar una imagen de Airflow Docker que generará sus cambios en tiempo real, para ver que sus dependencias están en su lugar, e incluso importa las variables de producción de AirFlow, por lo que puede ver los comandos renderizados correctamente.
Disclaimer: en la imagen de Docker solo iniciamos el servidor web porque no queremos que las cosas se ejecuten desde una computadora local y potencialmente tengan un impacto real en la producción.
Otra capacidad que brindamos para verificar que todo funcione como debe ser, es ejecutar pruebas en el repositorio local. Usando un script, cargamos todo el repositorio local en un objeto DagBag. Al hacerlo, tenemos todos los dags analizados como un árbol de dependencia, tal como los ve el planificador. Los errores se detectan durante la importación y la prueba fallará.
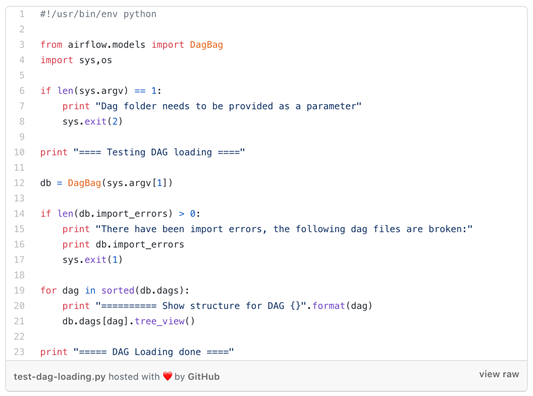
Después de que las pruebas locales pasan con éxito, los desarrolladores ejecutan un trabajo de Jenkins, que esencialmente ejecuta las mismas pruebas, como un mecanismo de seguridad. Después de que la compilación pase correctamente, cuando sea necesario, las variables en el panel de control de Airflow también se actualizan. Los DAG se cargan en un bucket S3 y luego se llevan al servidor NFS para que los diversos componentes de Airflow vean el código actualizado al mismo tiempo.
Para cambios importantes de infraestructura, tenemos una configuración separada y más completa que incluye un clúster Airflow de prueba. Esto nos permite probar cualquier cambio importante en la infraestructura o un cambio importante realizado a uno de los operadores al implementarlo desde una rama de trabajo en el grupo de Airflow de prueba, antes de implementarlo en nuestra operación de producción de Airflow.
Alertas y Monitoreo
La definición de alertas y monitoreo adecuados es una de las cosas más importantes de cualquier componente de AppsFlyer. Además de monitorear las métricas básicas del host de la CPU, la memoria, el uso del disco, etc… También hemos creado paneles basados en la base de datos de metadatos de Airflow usando la fuente de datos Grafana PostgreSQL para tener análisis sobre el éxito / fracaso de los trabajos.
En el lado de las alertas, hemos creado algunos trucos que nos hacen la vida un poco más fácil:
- Alertas Mixin-
Cada operador que creamos hereda de alerta mixin que creamos. Así es como definimos alertas en los trabajos fallidos.
Cada trabajo está configurado con una política de alerta predefinida, y cuando un trabajo falla, activamos esta política de alerta para notificar al propietario del trabajo que recuperamos del campo Propietario en el nivel DAG/trabajo.

Nuestra políticas predefinidas para alertas

Así es como se ven las alertas a nivel de trabajo
- Alertas SLA Airflow –
Si bien Airflow tiene su propio SLA por defecto, no satisface suficientemente nuestras necesidades. Mientras Airflow mide su SLA con tiempo y puede ejecutar una devolución de llamada personalizada en el incumplimiento, en AppsFlyer, queremos ejecutar verificaciones de SLA en parámetros adicionales, tal como si el DAG ni siquiera se ejecutó, o si varios trabajos (que se ejecutan cada hora) han fallado. Para hacerlo, escribimos nuestro propio sistema que analiza la base de datos de metadatos y verifica si se violaron las reglas SLA predefinidas. Este flujo también cubre el escenario donde Airflow está completamente inactivo y no nos dimos cuenta.

Tipos de SLA verificados que podemos definir para cada tarea
En conclusión, AppsFlyer realmente ama Airflow. Su simplicidad nos permite ser tan versátiles como queramos. El escalado es fácil y el costo de mantenimiento es realmente bajo.
Todavía tenemos un largo camino por recorrer con la gestión de permisos adecuada, mejorando el flujo de CI / CD y algunas características más en las que estamos pensando, pero Airflow hace que nuestras vidas sean mucho más fáciles, y te invito a que lo revises si estás buscando tener una solución sólida para organizar los flujos de trabajo de planeación de sus operaciones a gran escala.
Graciasa Elad Leev, Sharone Zitzman, Barak Gitsis, and Moshe Derri.
Traducción al español Ada Palazuelos