
How AppsFlyer uses Apache Airflow to run more than 3.5k daily jobs

Feb 27 · 8 min read


AppsFlyer’s real-world Airflow operation
AppsFlyer is essentially a big data company, we receive huge amounts of data daily from our SDKs, transform and normalize this data, and then eventually present it in our dashboard with different metrics and cohorts that are relevant to our users — pretty basic right?
Things become increasingly complex when you give context to the volume of the events, and in our case, we’re talking about more than 90B events daily and around 200TB of daily data that is ingested into our system to AWS S3.
AppsFlyer Engineering is always hiring, just like our product’s always-on, 24/7 SLAs. >> Learn More
In order to process and compute all these events, AppsFlyer maintains around 50 Hadoop clusters (vanilla with an in-house auto-scaling system) that runs over 3.5k+ daily Spark jobs that slice, dice and pivot the data around to give our customers the most precise data they need.
One of the core technologies enabling and supporting this scale of data operations is Apache Airflow, that schedules and executes all of these jobs, across the various clusters, while being aware of the different characteristics of each job.
What is Apache Airflow in a nutshell?
From the documentation:
Airflow is a platform to programmatically author, schedule and monitor workflows.
Use Airflow to author workflows as Directed Acyclic Graphs (DAGs) of tasks. The Airflow scheduler executes your tasks on an array of workers while following the specified dependencies. Rich command line utilities make performing complex surgeries on DAGs a snap. The rich user interface makes it easy to visualize pipelines running in production, monitor progress, and troubleshoot issues when needed.
When workflows are defined as code, they become more maintainable, versionable, testable, and collaborative.
Think about Airflow like a cron server, but with a lot of features like designing workflows, that are fully customizable with a great UI alongside centralized logging.
Architecture
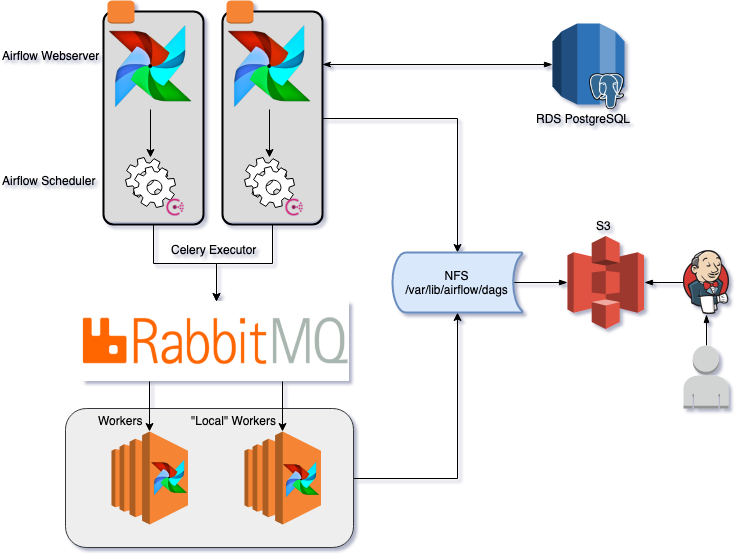
Airflow Architecture at AppsFlyer
Airflow is crucial for AppsFlyer’s core business as this is where the large majority of our ETL tasks run, as well as many others. With this in mind, we had to take a stability first approach, and we made sure that every part of Airflow is highly available:
- For the metadata DB, we use PostgreSQL which is managed, backed up and has a backup read replica through AWS RDS service.
- Airflow’s web servers run on multiple instances, with a Consul load balancer in front of them to distribute the requests between them.
- The scheduler is the one component in Airflow that is not designed for high availability, although we managed to work around this by using Consul locks. We run the scheduler process wrapped with the lock command. In this way, we make sure that only one instance of the scheduler is up, and if the instance fails, the lock releases which will then trigger another server to restart the service.
- We use CeleryExecutor with a RabbitMQ backend as the executor, this way we can spin up multiple worker machines, with a different purpose (separated by the queue). Also, RabbitMQ is a highly available cluster in itself.
- To make sure that the workers, the scheduler and the web servers are running with the same files, we mounted an NFS between all the components. This NFS is the target of the Jenkins job that we use to deploy any changes (will elaborate on that later).
As mentioned previously, we support about 50 different Hadoop clusters, and all Spark versions since 1.6, for this we created our own SparkOperator that receives the required data as a parameter.

Besides the actual operator that runs the Spark job, we have many more operators that are used to scale our clusters, whether EC2 spot nodes or on-demands to be able to run the actual task.
This is a result of learning that as a byproduct of managing the Hadoop clusters ourselves, we often find out that one of the clusters is malfunctioning and need to redirect all the jobs from the malfunctioning one to a different cluster. To make this possible, we created a way to override the actual hadoop_cluster parameter that the user enters at runtime, this is done through a dictionary that we enter as an Airflow variable that looks like this:

This dictionary notes that cluster “010” was changed to “110”, and every spark job that was supposed to run on “010” will run on “110” instead.
Docker Operator
We break our executed tasks into two different workloads:
- Tasks that require external resources to run— for example, Spark running in cluster mode. These spark-submit tasks are running with a low amount of local resources, as we are running everything in deploy-mode cluster.
- Tasks that require local resources, like compute, memory or storage.
These two workloads are complex when running on a single instance, and that’s why we understood we needed to create complete isolation. Fortunately, the fact that we use CeleryExecutor introduced an added advantage. We created two sets of Airflow workers, where each listens to its own queue. One set of machines is a general type, and the second has more computing resources.
Because AppsFlyer was already heavily invested in technical services that are bundled inside a Docker container, it was a given to use this ready-made tech stack in Airflow as well.
Once a repository is built in Jenkins, the code automatically gets containerized and uploaded into Artifactory. From there, we use an internally built Docker operator, that allows us to get and execute these containers inside of the Airflow workers. Another benefit that we gain from this is the fact that all of the required resources & code dependencies, such as packages, modules, and other resources, are already packaged inside the Docker image, and we don’t need to install anything on the workers themselves.
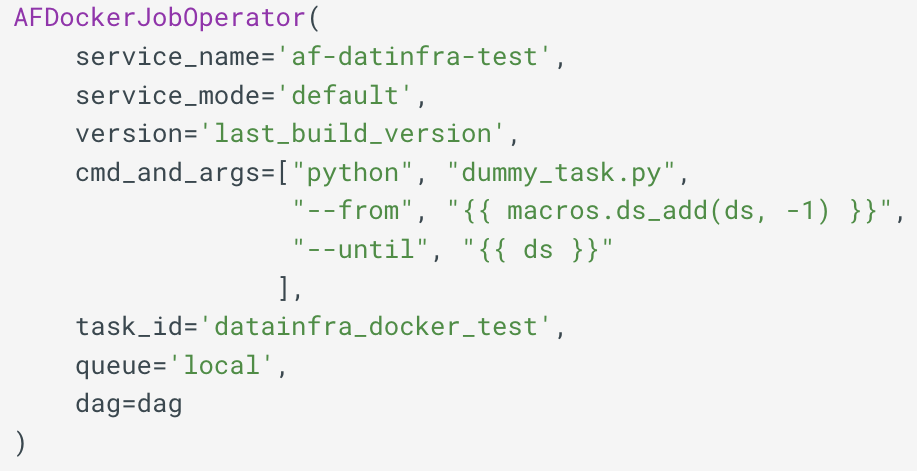
Docker Job operator, note that the queue parameter is different between AfDockerJobOperator and the SparkOperatorWithHook in the previous section
Airflow Variables
Airflow variables is a key-value store inside of Airflow’s metadata database. AppsFlyer loves the flexibility this provides a bit too much, we use it to store common parameters for multiple jobs, specifying the number of nodes in a specific cluster (for the scaling operators), reusability of commonly used jars… We really just use it everywhere. That’s why, it’s no real surprise that we had several production issues directly related to variables changes. Where the thing that is missing for us, is proper auditing, validation, and proper CI to understand if the variable change breaks the DAG itself.
This was another opportunity to build it ourselves. To accomplish this task, first we added LDAP authentication to the Airflow web server. Doing so, allowed us to separate the users based on the LDAP groups, we decided that regular users will be prohibited from viewing the Admin page (user_filter in Airflow’s configuration) — but this also created the unwanted byproduct of eliminating the Variables page view. To make the flow more user-friendly, we created a new tab in the UI and added a view-only section for the variables.

Changes to variables are made from within a Git repo, and we invoke a deployment pipeline that updates the metadata DB itself with the latest variables. The fact that it’s from a Git repo allows us to audit, revert and see the changes easily.
Development Workflow
In AppsFlyer, we aim to give the developer a simpler and transparent experience. To do so, our operator’s code is inside a common directory as the DAG’s definition themselves, to provide full transparency of the “infrastructure” code.
Once the developers perform changes on their local computer, they can spin up an Airflow Docker image that will render their changes in real-time — to see that their dependencies are in place, and it even imports the variables from the production Airflow, so they can see the rendered commands properly.
Disclaimer: In the Docker image we only start the webserver because we don’t want stuff running from a local computer and potentially have real production impact.
Another capability that we provide to verify that everything is working as it should, is to run tests on the local repository. Using a script, we load the entire local repo to a DagBag object. By doing so, we have all the dags parsed as a dependency tree, just as the scheduler sees them. Errors are caught during import, and the test will fail.
After the local tests pass successfully, the developers run a Jenkins job, that essentially runs the same tests, as a safety mechanism. After the build passes properly, when needed, the variables in the Airflow dashboard are also updated. The DAG’s themselves are uploaded to an S3 bucket, and then they are pulled to the NFS server so that the various Airflow components will see the updated code at the same time.
For major infrastructure changes, we have a separate and more comprehensive setup that includes a test Airflow cluster. This enables us to test any major infrastructure change or a breaking change made to one of the operators by deploying it from a working branch to the test Airflow cluster, before deploying to our production Airflow operation.
Alerting & Monitoring
Defining proper alerting and monitoring is one of the most important things with any AppsFlyer component. Besides monitoring the basic host metrics of CPU, memory, disk usage,… We have also created dashboards based on Airflow’s metadata DB using Grafana PostgreSQL data source to have analytics on success/failure of the jobs.
On the alerting side, we have created a few hacks that make our life a bit easier:
- Alerting Mixin-
Each operator we create inherits from alerting mixin we created. This is how we define alerts on the failed jobs.
Each job is configured with a predefined alerting policy, and when a job fails, we trigger this alerting policy to notify the job owner, that we retrieve from the Owner field at the DAG/job level.

Our predefined alerting policies


This is how it looks on the job level
- Airflow SLA Alerts-
While Airflow does have its own SLA by default, it doesn’t sufficiently suit our needs. While Airflow measures its SLA with time and can run a custom callback on the breach, at AppsFlyer, we want to run SLA checks on additional parameters, such as if the DAG didn’t even run, or if several jobs (that run hourly) failed. To do so, we wrote our own system that looks at the metadata DB and checks if predefined SLA rules were breached. This flow also covers the scenario where Airflow is completely down and we weren’t aware of it.

Types of SLA checks we can define per each task
In conclusion, AppsFlyer really loves Airflow. Its simplicity allows us to be as versatile as we want. Scaling is easy, and the maintenance cost is really low.
We still have a long way to go with proper permission management, improving the CI/CD flow, and a few more features that we are thinking about, but Airflow does make our lives much easier, and I’d encourage you to check it out if you are looking to have a robust solution to orchestrate scheduling workflows of your large-scale operations.
AppsFlyer
AppsFlyer Engineering
Thanks to Elad Leev, Sharone Zitzman, Barak Gitsis, and Moshe Derri.