
Analizamos Pulumi: Infraestructura como Código (Parte II)

Este tutorial esta basado en el tutorial de primeros pasos de pulumi el cual puede consultar aqui: https://www.pulumi.com/docs/get-started/aws/
En el articulo anterior dimos un vistazo acerca de como Pulumi puede ayudarnos al despliegue de infraestructura a través de código no propietario. Ademas vimos algunas de las ventajas y las principales partes que componen esta herramienta. En este articulo vamos a desplegar un pequeño bucket S3 en AWS. Ademas, echaremos un vistazo de como se definen los recursos a nivel de código.
Para este tutorial utilizaremos las librerias @pulumi/pulumi y la libreria @pulumi/aws. Desarrollaremos con el lenguaje de programacion typescript y desplegando en AWS.
Instalación de Pulumi
Para poder utilizar esta herramienta, es necesario tenerla instalada previamente. Pulumi es de código abierto y su repositorio esta disponible la pagina de pulumi github. Para la instalación deberemos seguir los siguientes pasos:
Paso 1: Ejecutar el comando de la figura 1. Esto nos descargara un binario que luego sera ejecutado. Tal como vemos en la figura 1, se desplegará una leyenda que indica que pulumi esta siendo descargado, en este caso vemos que la versión descargada es la v2.17.2.

Figura 1: Comando de instalación de pulumi
Paso 2: Verificar que la instalación se realizo correctamente. Para ello ejecutaremos el comando pulumi versión. La figura 2 muestra que la versión que descargamos e instalamos es la 2.17.2. Se puede consultar los cambios de cada release en los CHANGELOG de pulumi.

Figura 2: comprobación de versión
Configuración de credenciales de AWS
IMPORTANTE: Dado que este tutorial esta dirigido a usuarios de aws ,los pasos que se indican a continuación solo son validos para usuarios de Amazon web Services. Para los otros proveedores deberá consultar la documentación de Pulumi [1].
Dado que Pulumi deberá acceder a los recursos de AWS sera necesario tener las credenciales configuradas previamente para hacer esto posible. Si usted ya configuro las credenciales con AWS CLI, Pulumi tomara las variables de entornos ya definidas, caso contrario sera necesario definir las variables de entorno AWS_ACCESS_KEY_ID y AWS_SECRET_ACCESS_KEY . Otra acotación importante es que deberemos usar una cuenta IAM con accesos de usuario programático de manera de hacer posible la conexión entre Pulumi y el provider.
Paso 3: A continuación crearemos una carpeta donde se alojara nuestro proyecto, y dentro encontraremos todos los archivos necesarios para hacer funcionar nuestro aplicación con Pulumi. En la figura 3 se muestran los comandos que se deberán ejecutar. Como se puede ver , el primer comando pertenece a un login, en este caso inicié sesion localmente, esto provocará que la información perteneciente a mi stack, junto con las credenciales y secretos estarán disponible en la carpeta .pulumi , sin embargo Pulumi ofrece servicios para el mantenimiento de los stack, almacenamiento de secrets, para mas información consulte la documentación.
IMPORTANTE: El uso de tener los stack localmente no es una buena práctica para equipos de desarrollo, puesto que nuestra información del estado de nuestra infraestructura no estará disponible para todo el equipo, lo que puede conllevar a futuras inconsistencias.
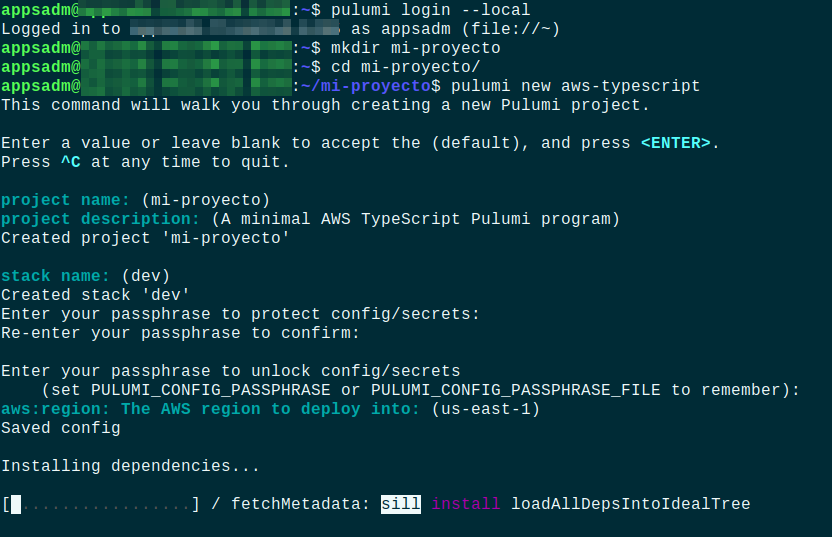
Figura 3: paso creacion de proyecto
En la figura 3 podemos ver distintas partes que son importantes para la creación de proyectos, y que son:
- Nombre del proyecto: es el nombre asignado para su proyecto y con el cual lo identificaremos.
- Descripción del proyecto: Una breve descripción que nos de información acerca de nuestro proyecto.
- Stack Name: Dado que Pulumi permite trabajar con múltiples stacks, y con motivos de configuración, es necesario ingresar al menos uno. La utilización de stack permite almacenar los estados de infraestructura de los distintos ambientes. Por ejemplo, podemos guardar el estado de un ambiente no productivo donde se probarán despliegues de desarrollo en el cual usaremos el stack dev (develop) y una vez validado esto, podemos crear otro stack donde almacenaremos el estado de un ambiente productivo, por ejemplo el stack production. Estos Stacks sirven como “bases de datos” de estados de nuestra infraestructura, y que son consultados por el engine de Pulumi para realizar una operacion de comparación y verificar el estado actual con el almacenado y así aplicar cambios, en caso de ser necesario.
Una vez realizada la configuración Pulumi comenzara la descarga de las dependencias que son necesarias para su funcionamiento, y , una vez finalizado, el proyecto estará disponible para que nosotros podamos modificarlo a nuestra necesidad.
Conociendo el código.
Si esta familiarizado con algún lenguaje de programación, y/o con el paradigma de programación orientada a objetos, no sera difícil entender las partes que componen el código. Sin embargo, vamos a explicar como se estructura cada componente. Para mas información acerca de los componentes puede consultar las API de Pulumi en su documentación [2].
La Figura 4 muestra la definición de código para la creación de un bucket en S3.
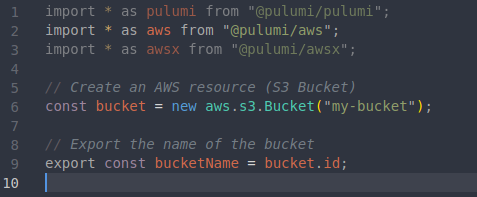
Figura 4: Creación de un bucket
En las lineas 1,2,3 podemos ver la importación de los paquetes necesarios para la creación de nuestros recursos. El paquete Pulumi contiene funcionalidades que permiten realizar operaciones a nivel objetos, stack y flujos de entrada y salida sobre nuestros recursos. El paquete @pulumi/aws contiene todas las apis para la creación de recursos junto con las operaciones asociadas a ellos.
La linea 6 es donde crearemos nuestro bucket. Generalmente, la generación de recursos consta de tres partes fundamentales (a la cual yo llamo tripla de definición) . La figura 5 muestra otra forma equivalente de generar un bucket como lo hicimos en la figura 4, pero con dos partes mas que describiremos a continuación.
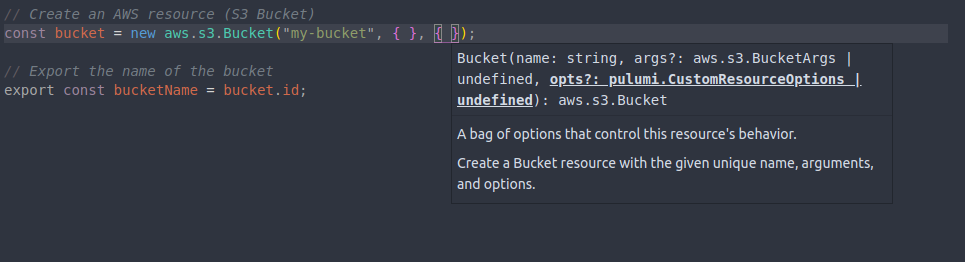
Figura 5: Forma equivalente de definir un bucket
Para crear un recurso, generalmente se hace a través de una operación new de un objeto recurso que recibe como argumento una tripla formada por:
- Nombre: como un tipo string, el cual identifica univocamente a un objeto a nivel Pulumi. Con esto se formara un urn (universal resource name) el cual el engine de Pulumi usará para identificar ese recurso. Notese que este nombre, no es el que corresponde al del recurso declarado en su proveedor (aunque podría serlo si usted desea), sino al perteneciente a su recurso a nivel Pulumi.
- Args (Argumentos) : Cada api define sus propios argumentos, con los cuales se construirá el recurso en Pulumi para luego desplegarlo en la nube. Debe consultar los argumentos en las referencias a las API de pulumi[2], ya que cada recurso cuenta con tipos de argumentos diferentes.
- Opts (opciones): Estas opciones permiten tomar algunos comportamientos en cuanto a la creación de los recursos, asi como también definir relaciones con otros recursos. En este caso deberá consultar a la api de Pulumi[2] .
En el caso de la imagen 5, Args y Opts los declaré como vacío, es decir sin argumentos y sin opciones, esto me creara un Bucket con valores por default. En la imagen 6, declare el bucket con un solo argumento el cual define un prefijo para el bucket (de tipo string) , ademas cree una opción para borrar el bucket antes de ser reemplazado (comportamiento del recurso).
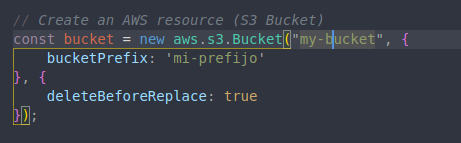
Figura 6: Definición con argumentos y opciones
Es necesario leer la documentación de las API de recursos, dado que cada recurso tiene su propia definición y métodos. Si bien Pulumi permite crear nuevos recursos, también permite importar recursos existentes, pero esto lo veremos en otra entrada. Ademas, permite crear recursos personalizados utilizando a los recursos ya existentes como recursos “primitivos”, este tema también se abordara en futuras entradas.
Probando y desplegando
Como se había mencionado anteriormente, Pulumi cuenta con una CLI, la cual la instalamos en los pasos previos. Esta CLI tiene una serie de comandos que podemos revisarlos en la documentacion [3]. Sin embargo, usaremos dos de ellos los cuales son importantes para el despliege, el comando preview y up.
- Vista previa (pulumi preview) : este comando nos permite tener una vista previa de aquella operación que se va a realizar sobre nuestros recursos. Las operaciones pueden ser crear, eliminar, modificar, importar y reemplazar. La Figura 7 muestra un Pulumi preview, donde podemos ver información como el tipo de componente, en este caso un recurso de aws s3 y que es un bucket, el nombre con el cual lo identificamos en nuestro entorno Pulumi y el plan que nos muestra la operación a ser realizada. Mas abajo podemos observar un resumen acerca de las operaciones que se realizaran sobre los recursos.
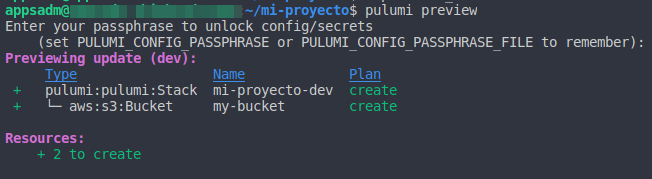
Figura 7: Comando de vista preeliminar
2. Upgrade (pulumi up): Pulumi up o pulumi upgrade nos permite aplicar los cambios. Si bien cuando realizamos esta accion primero tenemos una vista previa, luego se nos desplegaran 3 opciones para responder a la pregunta que nos hace pulumi para realizar los cambios, esto se muestra en la figura 8. Si le damos enter en si, simplemente la operacion de upgrade sobre nuestros recursos comenzara, si le damos no simplemente no se realizaran los cambios y si le damos a details se mostraran detalles como muestra en la figura 8.
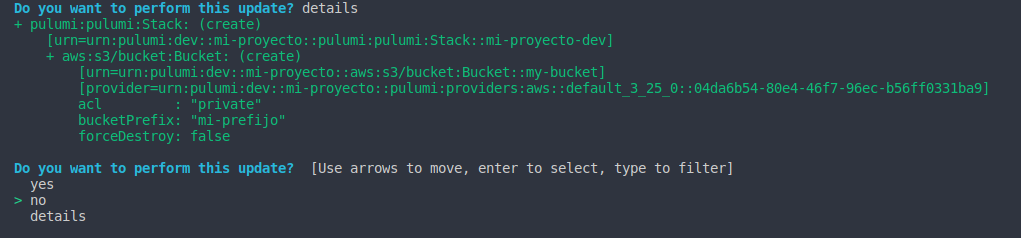
Figura 8: Opción detalles en comando upgrade
Como vemos, nos mostrará información mas detallada tal como: universal resource name (urn) de nuestro proyecto, urn de nuestro bucket y ademas las opciones y argumentos que le pasamos a través del constructor. El despliegue de detalles es sumamente importante cuando tenemos una gran cantidad de cambios y queremos corroborar si no existen errores al querer realizar la actualización. En la figura 9 vemos como se despliega la pantalla al aceptar estos cambios con una leyenda en el estado que indica que los componentes se están creando.

Figura 9: Cambios en estado creating
Una vez finalizado, como indica la figura 10, vemos los cambios ya realizados junto con información extra acerca de nuestros recursos.
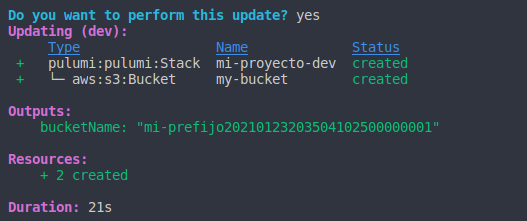
Figura 10: Recursos creados con exito
Una vez finalizado con esto, podemos ir a nuestra sección de bucket de S3 y ver como la creación se realizo correctamente.
Resumen.
En esta oportunidad, vimos como crear un bucket S3 en aws desde cero. Vimos como aprovechar la potencia de los lenguajes no propietarios como por ejemplo typescript junto con el paradigma de orientación a objetos, los cuales brindan una gran flexibilidad para generar nuevos recursos. Ademas, repasamos acerca de la potencia de Pulumi al crear multiples Stack que sirven como bases de datos que almacenan el estado de nuestra infraestructura actual. Cabe destacar que Pulumi tiene soporte para lenguajes como .NET, JavaScript y Go , asi como también soporte multi nube como AWS, Azure, GCP entre otros. Esto no solamente hace que la potencia de esta herramienta se centre en los lenguajes sino también en la flexibilidad multi cloud.
Bibliografia.
[1] Documentacion de pulumi: https://www.pulumi.com/docs/
[2] Referencias a las APIs: https://www.pulumi.com/docs/reference/pkg/
Tutorial de primeros pasos de Pulumi: https://www.pulumi.com/docs/get-started/aws/
Github Pulumi: https://github.com/pulumi
Imagen cabecera extraida de : https://www.pulumi.com/blog/enforcing-different-kinds-of-policies-for-cloud-resources/