
La caída de AWS paralizó medio Internet. ¿Cómo afectó en España?
El lunes 20 de octubre de 2025, Amazon Web Services (AWS), considerado el pilar de la infraestructura moderna de internet, sufrió una interrupción de servicio grave y prolongada de hasta 15 horas.
Origen de la caída de Amazon Web Services
Originado en su región US-EAST-1 (Virginia del Norte), el fallo se propagó a nivel mundial, interrumpiendo miles de servicios digitales y extendiéndose por más de 15 horas hasta la restauración completa.
Este evento sistémico, que afectó a más de 108 servicios de AWS, ha sido calificado como una advertencia contundente frente a los riesgos de la “monocultura tecnológica” y la dependencia excesiva de un puñado de proveedores de nube.
La causa raíz del incidente no fue un fallo de hardware, sino una reacción en cadena compleja.
La chispa inicial fue un problema de resolución del Sistema de Nombres de Dominio (DNS) que afectó al servicio de base de datos DynamoDB en US-EAST-1.
El DNS, que actúa como la “guía telefónica” de internet, al fallar hizo que DynamoDB fuera efectivamente invisible para los servicios dependientes.
Este detonante inicial deterioró la red interna de EC2 y, crucialmente, el subsistema que monitoriza la salud de los balanceadores de carga de red (Network Load Balancers).
El fallo en esta “meta-infraestructura” generó un bucle de degradación que paralizó más de un centenar de servicios de AWS.
La gravedad se explica porque US-EAST-1 alberga el plano de control común para servicios globales como IAM (Identity and Access Management) y las Tablas Globales de DynamoDB.
Su degradación afectó la gestión de operaciones en Europa, Asia y otras regiones.
Impacto Global: Sectores Inmunes Cero
El impacto económico global del apagón se estima en cientos de miles de millones de dólares.
El alcance de la disrupción demostró que ningún sector digital era inmune.
La plataforma Downdetector registró más de 11 millones de informes de usuarios en más de 2.500 empresas.
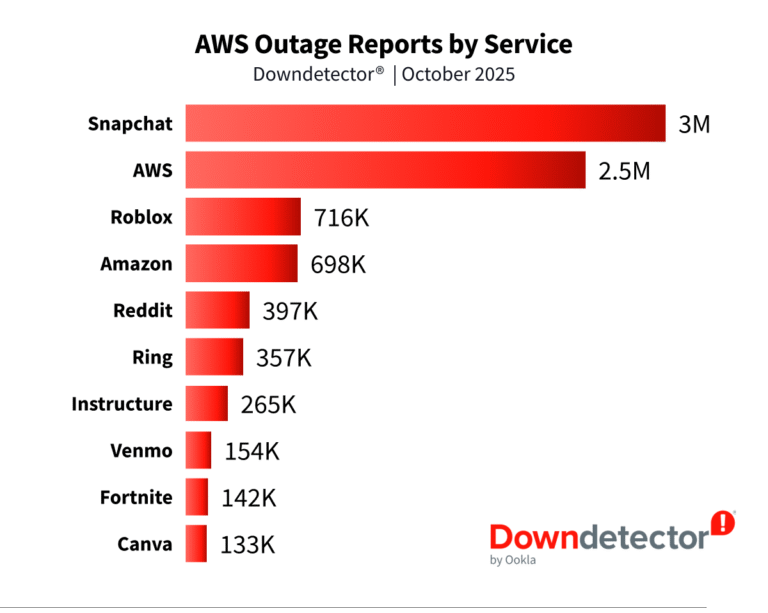
Entre los afectados:
Redes Sociales y Comunicación: Snapchat, Slack, WhatsApp, Zoom y Reddit sufrieron fallos de inicio de sesión y mensajes.
Entretenimiento y Juegos: Fortnite, Netflix, Disney+, Roblox y PlayStation Network experimentaron desconexiones y errores de reproducción.
Finanzas y Criptomonedas: Coinbase, Robinhood, Venmo y Chime reportaron interrupciones en pagos y transferencias.
Infraestructura Crítica: Aerolíneas como Delta y United, y portales gubernamentales (como el HMRC británico), registraron fallos de sistema.
AWS en España: Colapso de pagos digitales
Uno de los casos más alarmantes ocurrió en España, donde la infraestructura de pagos digitales sufrió un colapso casi total.
Durante el apagón, Redsys, el principal procesador de pagos del país, experimentó una interrupción masiva.
Consecuencias inmediatas:
Datáfonos (TPV) inoperativos en comercios y gasolineras, forzando el uso de efectivo.
Bizum quedó inoperativo para clientes de BBVA, Santander, CaixaBank y Sabadell.
Cajeros automáticos con fallos que impidieron retirar efectivo.
Aunque Redsys negó oficialmente la relación con AWS y atribuyó el problema a un “fallo temporal de comunicaciones internas”, la simultaneidad de los fallos generó sospechas.
El evento demostró que la capacidad de España para realizar transacciones básicas depende de un punto único de fallo, exponiendo una fragilidad sistémica en su infraestructura financiera.
El Imperativo de la Resiliencia
El colapso de AWS del 20 de octubre de 2025 marca un punto de inflexión: de la narrativa de ahorro y conveniencia, hacia una centrada en la resiliencia digital y la gestión de riesgos.
La dependencia de unos pocos hyperscalers (AWS, Azure, Google Cloud) crea un defecto sistémico global, donde un solo fallo puede “pausar internet”.
Lecciones clave para las empresas:
Diversificación Multinube: Adoptar estrategias multirregión y multinube para activar conmutación por error (failover) hacia otros proveedores.
Mapeo de Dependencias: Mantener un registro detallado de servicios críticos y sus interdependencias (EC2, S3, IAM, etc.).
Pruebas de Resiliencia: Realizar simulacros de recuperación de desastres y conmutación por error de forma regular.
El incidente subraya la necesidad de abandonar la confianza ciega en los SLA y adoptar un enfoque proactivo de continuidad de negocio.
Las grandes corporaciones deben implementar estrategias multinube, pero las PYMES siguen siendo altamente vulnerables.
Este colapso podría marcar el inicio de un nuevo marco regulatorio que exija mayor transparencia sobre las dependencias arquitectónicas de los proveedores de nube.
Recibe nuestra Newsletter de Cloud semanal
SmartClouds helps businesses get in front of the right technical audience. We are experts in content creation and community management. We’ll help you showcase your products and the problems you solve.